
Ajax is a technique for creating seamless interactive websites via asynchronous data exchange between client and server. Ajax facilitates communication with the server via partial page updates instead of the traditional full-page refresh.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/AJAX.md" }, { "name": "AMD", "description": "a standard defining how to load JavaScript libraries or modules asynchronously", "markdown": "\n\n# AMD\n\n[AMD](https://github.com/amdjs/amdjs-api/wiki/AMD) stands for Asynchronous Module Definition. It is an alternative to [CommonJS (CJS)](/_glossary/COMMONJS.md) specification.\n\nThe API specifies a mechanism for defining modules such that the module and its dependencies can be asynchronously loaded. This is particularly well suited for the browser environment where synchronous loading of modules incurs performance, usability, debugging, and cross-domain access problems.\n\nAMD libraries expose a global `define` function whose footprint is\n\n```js\ndefine(modulename?,[dependencyA?, dependencyB?, …], function (objectA, objectB, …) {\n...\n var myExportedObj = function() { … }\n return myExportedObj;\n\n});\n```\n\nWhere\n\n- `modulename` is an optional string parameter to explicitly declare the id of the current module\n- `dependencyA`, `dependencyB` and so on, are the dependencies for the current module\n- `function(objectA, objectB) {...}` is a factory whose arguments are the exported objects of each dependency.\n- `myExportedObj` an optional return value (since a module might be just adding methods to an existing object) but, if declared, it would be this module’s exported object, which other modules would get if they list `modulename` among their dependencies.\n\nAside from the global `define` function, an AMD compliant library must have a `define.amd` property whose value is an object. Checking for the existence of both `define` and `define.amd` in the global scope allows any script to verify it is being called from an AMD loader.\n\nExamples of libraries providing AMD loading capabilities are:\n\n- [RequireJS](/_glossary/REQUIREJS.md) written by Mozilla’s [James Burke](https://github.com/jrburke/). One of the first ones to become widely used and still the most popular. It provides a limited interoperability with [CommonJS](/_glossary/COMMONJS.md) modules too.\n- [CurlJS](https://github.com/cujojs/curl) part of the [CujoJS Framework](http://cujojs.com/). CurlJS is less popular than RequireJS and is receiving only maintenance updates, no new features since 2014.\n- [Alameda](https://github.com/requirejs/alameda) also made by James Burke, it’s like RequireJS but using promises to manage the completion events.\n- [Cajon](https://github.com/requirejs/cajon) also made by James Burke, it’s like a decorator for RequireJS that replaces the `load` method to fetch dependencies through [AJAX](/_glossary/AJAX.md) calls.\n- [SystemJS](https://github.com/systemjs/systemjs) by [Guy Bedford](https://github.com/guybedford) who, until a couple of years ago, was one of the most active plugin developers for RequireJS. SystemJS can load AMD, CommonJS and [ES6](/_glossary/ECMASCRIPT.md) modules seamlessly and is mostly used in combination with [jspm](http://jspm.io/), which acts as a dependency manager (not unlike [Bower](/_glossary/BOWER.md)) leveraging in Github and [npm](/_glossary/NPM.md).\n\nAll these libraries allow for the developer to preview a project without any build step, requesting the dependencies asynchronously. There’s usually an optional (but reccomended) build or bundling step for production deploys, in order to minify the code and minimize the number of requests in order to enhance load times. Allegedly, the coming of [HTTP2](https://http2.github.io/) support in browsers and webservers should eliminate the need for extra requests when loading dependencies asynchronously, thus eliminating the need of a build step.\n\nOther libraries that can’t load dependencies asynchronously but can include AMD modules in their build workflow, are, for example:\n\n- [Webpack](/_glossary/WEBPACK.md)\n- [Rollup](http://rollupjs.org/)\n- [StealJS](http://stealjs.com/)\n", "html": "AMD stands for Asynchronous Module Definition. It is an alternative to CommonJS (CJS) specification.
\nThe API specifies a mechanism for defining modules such that the module and its dependencies can be asynchronously loaded. This is particularly well suited for the browser environment where synchronous loading of modules incurs performance, usability, debugging, and cross-domain access problems.
\nAMD libraries expose a global define function whose footprint is
define(modulename?,[dependencyA?, dependencyB?, …], function (objectA, objectB, …) {\n...\n var myExportedObj = function() { … }\n return myExportedObj;\n\n});\nWhere
\nmodulename is an optional string parameter to explicitly declare the id of the current moduledependencyA, dependencyB and so on, are the dependencies for the current modulefunction(objectA, objectB) {...} is a factory whose arguments are the exported objects of each dependency.myExportedObj an optional return value (since a module might be just adding methods to an existing object) but, if declared, it would be this module’s exported object, which other modules would get if they list modulename among their dependencies.Aside from the global define function, an AMD compliant library must have a define.amd property whose value is an object. Checking for the existence of both define and define.amd in the global scope allows any script to verify it is being called from an AMD loader.
Examples of libraries providing AMD loading capabilities are:
\nload method to fetch dependencies through AJAX calls.All these libraries allow for the developer to preview a project without any build step, requesting the dependencies asynchronously. There’s usually an optional (but reccomended) build or bundling step for production deploys, in order to minify the code and minimize the number of requests in order to enhance load times. Allegedly, the coming of HTTP2 support in browsers and webservers should eliminate the need for extra requests when loading dependencies asynchronously, thus eliminating the need of a build step.
\nOther libraries that can’t load dependencies asynchronously but can include AMD modules in their build workflow, are, for example:
\n\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/AMD.md" }, { "name": "AngularJS", "description": "a structural framework for dynamic web apps", "markdown": "\n\n# AngularJS\n\n[AngularJS](https://angularjs.org/) is a structural framework for dynamic web apps. It lets developers use HTML as their template language and lets them extend HTML’s syntax to express their application’s components clearly and succinctly.\n\nAngular’s data binding and dependency injection eliminate much of the code developers would otherwise have to write. And it all happens within the browser, making it an ideal partner with any server technology.\n", "html": "AngularJS is a structural framework for dynamic web apps. It lets developers use HTML as their template language and lets them extend HTML’s syntax to express their application’s components clearly and succinctly.
\nAngular’s data binding and dependency injection eliminate much of the code developers would otherwise have to write. And it all happens within the browser, making it an ideal partner with any server technology.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/ANGULARJS.md" }, { "name": "Apache Cordova", "description": "a popular mobile application development framework originally created by Nitobi", "markdown": "\n\n# PhoneGap\n\n[Apache Cordova](http://phonegap.com/) (formerly **PhoneGap**) is a popular mobile application development framework originally created by Nitobi. Adobe Systems purchased Nitobi in 2011, rebranded it as PhoneGap, and later released an open source version of the software called Apache Cordova. Apache Cordova enables software programmers to build applications for mobile devices using JavaScript, HTML5, and CSS3, instead of relying on platform-specific APIs like those in Android, iOS, or Windows Phone. It enables wrapping up of CSS, HTML, and JavaScript code depending upon the platform of the device. It extends the features of HTML and JavaScript to work with the device. The resulting applications are hybrid, meaning that they are neither truly native mobile application (because all layout rendering is done via Web views instead of the platform’s native UI framework) nor purely Web-based (because they are not just Web apps, but are packaged as apps for distribution and have access to native device APIs). Mixing native and hybrid code snippets has been possible since version 1.9.\n\nThe software was previously called just “PhoneGap”, then “Apache Callback”. As open-source software, Apache Cordova allows wrappers around it, such as Intel XDK or Appery.io.\n\nPhoneGap is Adobe’s productized version and ecosystem on top of Cordova. Like PhoneGap, many other tools and frameworks are also built on top of Cordova, including Ionic, the Intel XDK, Monaca, TACO, and the Telerik Platform. These tools use Cordova, and not PhoneGap for their core tools.\n\nContributors to the Apache Cordova project include Adobe, IBM, Google, Microsoft, Intel, BlackBerry, Mozilla, and others.\n\n## History\n\nFirst developed at an iPhoneDevCamp event in San Francisco, PhoneGap went on to win the People’s Choice Award at O’Reilly Media’s 2009 Web 2.0 Conference, and the framework has been used to develop many apps. Apple Inc. has confirmed that the framework has its approval, even with the new 4.0 developer license agreement changes. The PhoneGap framework is used by several mobile application platforms such as Asial’s Monaca, ViziApps, Worklight, Convertigo, and appMobi as the backbone of their mobile client development engine.\n\nAdobe officially announced the acquisition of Nitobi Software (the original developer) on October 4, 2011. Coincident with that, the PhoneGap code was contributed to the Apache Software Foundation to start a new project called Apache Cordova. The project’s original name, Apache Callback, was viewed as too generic. Then it also appears in Adobe Systems as Adobe PhoneGap and also as Adobe Phonegap Build.\n\nEarly versions of PhoneGap required an Apple computer to create iOS apps and a Windows computer to create Windows Mobile apps. After September 2012, Adobe’s PhoneGap Build service allows programmers to upload HTML, CSS, and JavaScript source code to a “cloud compiler” that generates apps for every supported platform.\n\n## Design and rationale\n\nThe core of Apache Cordova applications use HTML5 and CSS3 for their rendering and JavaScript for their logic. HTML5 now provides access to underlying hardware such as the accelerometer, camera, and GPS. However, browser support for HTML5-based device access is not consistent across mobile browsers, particularly older versions of Android. To overcome these limitations, Apache Cordova embeds HTML5 code inside a native WebView on the device, using a foreign function interface to access the native resources of the device.\n\nApache Cordova can be extended with native plug-ins that allow for developers to add functionality that can be called from JavaScript, allowing for direct communication between the native layer and the HTML5 page. Apache Cordova includes basic plugins that allow access to the device’s accelerometer, camera, microphone, compass, file system, and more.\n\nHowever, the use of Web-based technologies leads some Apache Cordova applications to run slower than native applications with similar functionality. Adobe Systems warns that applications may be rejected by Apple for being too slow or not feeling “native” enough (having appearance and functionality consistent with what users have come to expect on the platform). This can be an issue for some Apache Cordova applications.\n\n## Supported platforms\n\nAs of January 2016, Apache Cordova currently supports development for the operating systems Apple iOS, BlackBerry, Google Android, LG webOS, Microsoft Windows Phone (7 and 8), Nokia Symbian OS, Tizen (SDK 2.x), Bada, Firefox OS, and Ubuntu Touch. The table below is a list of supported features for each operating system.\n\n| Feature | iPhone | Android | Windows Phone | BlackBerry OS | Bada | Symbian | Tizen |\n| --- | --- | --- | --- | --- | --- | --- | --- |\n| Accelerometer | Yes | Yes | Yes | 5.0+ | Yes | Yes | Yes |\n| Camera | Yes | Yes | Yes | 5.0+ | Yes | Yes | Yes |\n| Compass | 3GS+ | Yes | Yes | 10+ | Yes | **N/A** | Yes |\n| Contacts | Yes | Yes | Yes | 5.0+ | Yes | Yes | Yes |\n| File | Yes | Yes | Yes | 5.0+ | Yes | **N/A** | Yes |\n| Geolocation | Yes | Yes | Yes | Yes | Yes | Yes | Yes |\n| Media | Yes | Yes | Yes | 10+ | **N/A** | **N/A** | Yes |\n| Network | Yes | Yes | Yes | Yes | Yes | Yes | Yes |\n| Notification | Yes | Yes | Yes | Yes | Yes | Yes | Yes |\n| Storage | Yes | Yes | Yes | 5.0+ | **N/A** | Yes | Yes |\n\n----------\n\n*Source:*\n\n- [Apache Cordova](https://en.wikipedia.org/wiki/Apache_Cordova)*. From Wikipedia, the free encyclopedia*\n", "html": "Apache Cordova (formerly PhoneGap) is a popular mobile application development framework originally created by Nitobi. Adobe Systems purchased Nitobi in 2011, rebranded it as PhoneGap, and later released an open source version of the software called Apache Cordova. Apache Cordova enables software programmers to build applications for mobile devices using JavaScript, HTML5, and CSS3, instead of relying on platform-specific APIs like those in Android, iOS, or Windows Phone. It enables wrapping up of CSS, HTML, and JavaScript code depending upon the platform of the device. It extends the features of HTML and JavaScript to work with the device. The resulting applications are hybrid, meaning that they are neither truly native mobile application (because all layout rendering is done via Web views instead of the platform’s native UI framework) nor purely Web-based (because they are not just Web apps, but are packaged as apps for distribution and have access to native device APIs). Mixing native and hybrid code snippets has been possible since version 1.9.
\nThe software was previously called just “PhoneGap”, then “Apache Callback”. As open-source software, Apache Cordova allows wrappers around it, such as Intel XDK or Appery.io.
\nPhoneGap is Adobe’s productized version and ecosystem on top of Cordova. Like PhoneGap, many other tools and frameworks are also built on top of Cordova, including Ionic, the Intel XDK, Monaca, TACO, and the Telerik Platform. These tools use Cordova, and not PhoneGap for their core tools.
\nContributors to the Apache Cordova project include Adobe, IBM, Google, Microsoft, Intel, BlackBerry, Mozilla, and others.
\nFirst developed at an iPhoneDevCamp event in San Francisco, PhoneGap went on to win the People’s Choice Award at O’Reilly Media’s 2009 Web 2.0 Conference, and the framework has been used to develop many apps. Apple Inc. has confirmed that the framework has its approval, even with the new 4.0 developer license agreement changes. The PhoneGap framework is used by several mobile application platforms such as Asial’s Monaca, ViziApps, Worklight, Convertigo, and appMobi as the backbone of their mobile client development engine.
\nAdobe officially announced the acquisition of Nitobi Software (the original developer) on October 4, 2011. Coincident with that, the PhoneGap code was contributed to the Apache Software Foundation to start a new project called Apache Cordova. The project’s original name, Apache Callback, was viewed as too generic. Then it also appears in Adobe Systems as Adobe PhoneGap and also as Adobe Phonegap Build.
\nEarly versions of PhoneGap required an Apple computer to create iOS apps and a Windows computer to create Windows Mobile apps. After September 2012, Adobe’s PhoneGap Build service allows programmers to upload HTML, CSS, and JavaScript source code to a “cloud compiler” that generates apps for every supported platform.
\nThe core of Apache Cordova applications use HTML5 and CSS3 for their rendering and JavaScript for their logic. HTML5 now provides access to underlying hardware such as the accelerometer, camera, and GPS. However, browser support for HTML5-based device access is not consistent across mobile browsers, particularly older versions of Android. To overcome these limitations, Apache Cordova embeds HTML5 code inside a native WebView on the device, using a foreign function interface to access the native resources of the device.
\nApache Cordova can be extended with native plug-ins that allow for developers to add functionality that can be called from JavaScript, allowing for direct communication between the native layer and the HTML5 page. Apache Cordova includes basic plugins that allow access to the device’s accelerometer, camera, microphone, compass, file system, and more.
\nHowever, the use of Web-based technologies leads some Apache Cordova applications to run slower than native applications with similar functionality. Adobe Systems warns that applications may be rejected by Apple for being too slow or not feeling “native” enough (having appearance and functionality consistent with what users have come to expect on the platform). This can be an issue for some Apache Cordova applications.
\nAs of January 2016, Apache Cordova currently supports development for the operating systems Apple iOS, BlackBerry, Google Android, LG webOS, Microsoft Windows Phone (7 and 8), Nokia Symbian OS, Tizen (SDK 2.x), Bada, Firefox OS, and Ubuntu Touch. The table below is a list of supported features for each operating system.
\n| Feature | \niPhone | \nAndroid | \nWindows Phone | \nBlackBerry OS | \nBada | \nSymbian | \nTizen | \n
|---|---|---|---|---|---|---|---|
| Accelerometer | \nYes | \nYes | \nYes | \n5.0+ | \nYes | \nYes | \nYes | \n
| Camera | \nYes | \nYes | \nYes | \n5.0+ | \nYes | \nYes | \nYes | \n
| Compass | \n3GS+ | \nYes | \nYes | \n10+ | \nYes | \nN/A | \nYes | \n
| Contacts | \nYes | \nYes | \nYes | \n5.0+ | \nYes | \nYes | \nYes | \n
| File | \nYes | \nYes | \nYes | \n5.0+ | \nYes | \nN/A | \nYes | \n
| Geolocation | \nYes | \nYes | \nYes | \nYes | \nYes | \nYes | \nYes | \n
| Media | \nYes | \nYes | \nYes | \n10+ | \nN/A | \nN/A | \nYes | \n
| Network | \nYes | \nYes | \nYes | \nYes | \nYes | \nYes | \nYes | \n
| Notification | \nYes | \nYes | \nYes | \nYes | \nYes | \nYes | \nYes | \n
| Storage | \nYes | \nYes | \nYes | \n5.0+ | \nN/A | \nYes | \nYes | \n
Source:
\nArity (from Latin) is the term used to refer to the number of arguments or operands in a function or operation, respectively. You're most likely to come across this word in the realm of JavaScript when it’s used to mention the number of arguments expected by a JavaScript function.
\nThere’s even a property named arity, of the Function object that returns the number of expected arguments in a function. It’s now obsolete though and replaced by length.
As an example, the following function has an arity of 3.
\nfunction getName(first, middle, last) {\n return first + ' ' + middle + ' ' + last;\n}\nSource: https://gist.github.com/nucliweb/8de961282f64095b1a57.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/ARITY.md" }, { "name": "Babel", "description": "a JavaScript transformation toolkit which started as an ECMAScript 2015 / ES6 code translator (transpiler)", "markdown": "\n\n# Babel\n\n[Babel](https://babeljs.io/) (formerly *6to5*) is essentially an [ECMAScript](/_glossary/ECMASCRIPT.md) 2015 (ES6) and beyond transpiler. It means that it is a program that translates future’s JavaScript into today’s widely understood (by browsers) JavaScript. The idea behind such a tool is to allow developers to write their code using ECMAScript’s new features while still making it work in current (and past) environments.\n\nAs of [version 6](https://babeljs.io/blog/2015/10/29/6.0.0), Babel also intends to be a platform, a suite of tools designed to create the next generation of JavaScript tooling. This means Babel is also supposed to power minifiers, linters, formatters, syntax highlighters, code completion tools, type checkers, codemod tools, and every other tool to be using the same foundation to do their job better than ever before.\n", "html": "Babel (formerly 6to5) is essentially an ECMAScript 2015 (ES6) and beyond transpiler. It means that it is a program that translates future’s JavaScript into today’s widely understood (by browsers) JavaScript. The idea behind such a tool is to allow developers to write their code using ECMAScript’s new features while still making it work in current (and past) environments.
\nAs of version 6, Babel also intends to be a platform, a suite of tools designed to create the next generation of JavaScript tooling. This means Babel is also supposed to power minifiers, linters, formatters, syntax highlighters, code completion tools, type checkers, codemod tools, and every other tool to be using the same foundation to do their job better than ever before.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/BABEL.md" }, { "name": "Backbone", "description": "a structural framework for dynamic web apps", "markdown": "\n\n# Backbone\n\n[Backbone.js](http://backbonejs.org/) is a framework giving structure to web applications by providing models with key-value binding and custom events, collections with a rich API of enumerable functions, views with declarative event handling, and connects it all to existing APIs over a RESTful [JSON](/_glossary/JSON.md) interface.\n", "html": "Backbone.js is a framework giving structure to web applications by providing models with key-value binding and custom events, collections with a rich API of enumerable functions, views with declarative event handling, and connects it all to existing APIs over a RESTful JSON interface.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/BACKBONE.md" }, { "name": "BEM", "description": "a methodology and libraries developed and used at Yandex for building user interfaces", "markdown": "\n\n# BEM\n\n[BEM](https://en.bem.info/) is a methodology and libraries developed and used at Yandex for building user interfaces.\n\nKey concepts of methodology\n\n * Block: logically and functionally independent page component, encapsulates behavior (JavaScript), templates, styles (CSS), and other implementation technologies\n * Element: a constituent part of a block that can’t be used outside of it (For example, a menu item)\n * Modifier: defines the appearance and behavior of a block or an element\n\nBEM methodology solves common frontend problems:\n\n 1. Component approach (splitting interface into blocks).\n 2. How to name things (in [code](https://en.bem.info/method/naming-convention/) and on [filesystem](https://en.bem.info/method/filesystem/)).\n 3. How to reuse components (for JS / CSS and all other techs) — for example you can take [bem-core](https://github.com/bem/bem-core) library (a collection of common blocks and solutions).\n 4. How to describe components behaviour — [i-bem.js](https://en.bem.info/technology/i-bem/) library that allows you describe a block logic in declarative style and keep it loosely coupled with others.\n 5. How to generate HTML — declarative template engine [bem-xjst](https://github.com/bem/bem-xjst) for server and browsers.\n 6. How to manage components dependencies and build project — [ENB](https://github.com/enb/enb) builder.\n", "html": "BEM is a methodology and libraries developed and used at Yandex for building user interfaces.
\nKey concepts of methodology
\nBEM methodology solves common frontend problems:
\nBluebird is a fully featured promise library with focus on innovative features and performance. It means that it is a tool that completes and reinforces the behavior of JavaScript promises.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/BLUEBIRD.md" }, { "name": "Bower", "description": "a package manager for front-end dependencies", "markdown": "\n\n# Bower\n\n[Bower](http://bower.io/) is a package manager for front-end dependencies. It takes care of hunting, finding, downloading, saving these dependencies and keeping track of them in a manifest file called `bower.json`. Bower uses a flat dependency tree, requiring only one version for each package, reducing page load to a minimum.\n", "html": "Bower is a package manager for front-end dependencies. It takes care of hunting, finding, downloading, saving these dependencies and keeping track of them in a manifest file called bower.json. Bower uses a flat dependency tree, requiring only one version for each package, reducing page load to a minimum.
Broccoli is a fast, reliable asset pipeline, supporting constant-time rebuilds and compact build definitions. Comparable to the Rails asset pipeline in scope, though it runs on Node.js and is backend-agnostic.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/BROCCOLI.md" }, { "name": "Browserify", "description": "a tool making possible to use the `require` function from Node.js within the browser", "markdown": "\n\n# Browserify\n\n[Browserify](http://browserify.org/) is a tool that allows you to use the [require](https://nodejs.org/api/modules.html) [Node.js](/_glossary/NODEJS.md) function while working for the browser by bundling up all the required dependencies. \n\nThe idea behind Browserify is to make it possible to use existing libraries from [npm](/_glossary/NPM.md) even when writing code for the client side. To allow this, it goes through the code, request the required dependencies, then create a single file containing everything: both the dependencies and the code using them.\n", "html": "Browserify is a tool that allows you to use the require Node.js function while working for the browser by bundling up all the required dependencies.
\nThe idea behind Browserify is to make it possible to use existing libraries from npm even when writing code for the client side. To allow this, it goes through the code, request the required dependencies, then create a single file containing everything: both the dependencies and the code using them.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/BROWSERIFY.md" }, { "name": "Brunch", "description": "a tool focusing on the production of deployment-ready files from development files", "markdown": "\n\n# Brunch\n\n[Brunch](http://brunch.io/) is a builder. Not a generic task runner, but a specialized tool focusing on the production of a small number of deployment-ready files from a large number of heterogenous development files or trees.\n\nBrunch is fundamentally specialized and geared towards building assets, these files that get used in the end by the runtime platform, usually a web browser. It thus comes pre-equipped with a number of behaviors and features such as concatenation, minification and watching of source files.\n", "html": "Brunch is a builder. Not a generic task runner, but a specialized tool focusing on the production of a small number of deployment-ready files from a large number of heterogenous development files or trees.
\nBrunch is fundamentally specialized and geared towards building assets, these files that get used in the end by the runtime platform, usually a web browser. It thus comes pre-equipped with a number of behaviors and features such as concatenation, minification and watching of source files.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/BRUNCH.md" }, { "name": "Canvas", "description": "an HTML element for graphic applications in 2D or 3D", "markdown": "\n\n# Canvas\n\nThe [Canvas HTML-Element](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/canvas) allows access to individual pixels to enable fast drawing applications.\n\nIts API gives access to [WebGL](/_glossary/WEBGL.md) for 3D graphics and to the [2D drawing API](https://developer.mozilla.org/en-US/docs/Web/API/CanvasRenderingContext2D).\n", "html": "The Canvas HTML-Element allows access to individual pixels to enable fast drawing applications.
\nIts API gives access to WebGL for 3D graphics and to the 2D drawing API.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/CANVAS.md" }, { "name": "Chai", "description": "an assertion library used with a JavaScript testing framework", "markdown": "\n\n# Chai\n\n[Chai](http://chaijs.com/) is a Behavior Driven Development (BDD) / Test Driven Development (TDD) assertion library for [Node.js](/_glossary/NODEJS.md) and the browser. It can be paired with any JavaScript testing framework, such as [Mocha](/_glossary/MOCHA.md).\n\nThe Chai assertion library allows you to write assertions in the classical form: `assert.typeOf(foo, 'string')`, but where Chai shines is its chain-capable style which makes writing assertions very readable: `expect(foo).to.be.a('string')`.\n", "html": "Chai is a Behavior Driven Development (BDD) / Test Driven Development (TDD) assertion library for Node.js and the browser. It can be paired with any JavaScript testing framework, such as Mocha.
\nThe Chai assertion library allows you to write assertions in the classical form: assert.typeOf(foo, 'string'), but where Chai shines is its chain-capable style which makes writing assertions very readable: expect(foo).to.be.a('string').
Chakra is a JavaScript engine that powers Microsoft Edge and Windows applications written in HTML/CSS/JS.
\nChakra is open-sourced as ChakraCore and can optionally be used with Node.js instead of V8.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/CHAKRA.md" }, { "name": "Closure", "description": "a way of referencing variables from a child function while retaining their value even if it changes in the parent function", "markdown": "\n\n# Closure\n\nA closure is function that closes over its environment. It has access to the state of the environment, but the variables inside the closure are private.\n\nExample:\n\n```js\n(function (){\n var scopeVar = 'Hello';\n\n (function closure(){\n var closureVar = ' World';\n console.log(scopeVar + closureVar); \n })();\n})();\n```\n\n`scopeVar` is accessible inside the outer and the inner function, but `closureVar` is only accessible inside the inner function.\n", "html": "A closure is function that closes over its environment. It has access to the state of the environment, but the variables inside the closure are private.
\nExample:
\n(function (){\n var scopeVar = 'Hello';\n\n (function closure(){\n var closureVar = ' World';\n console.log(scopeVar + closureVar); \n })();\n})();\nscopeVar is accessible inside the outer and the inner function, but closureVar is only accessible inside the inner function.
The Closure Compiler is a tool for making JavaScript download and run faster. It is a true compiler for JavaScript. Instead of compiling from a source language to machine code, it compiles from JavaScript to better JavaScript. It parses your JavaScript, analyzes it, removes dead code and rewrites and minimizes what’s left. It also checks syntax, variable references, and types, and warns about common JavaScript pitfalls.
\nClosure-compiler requires java to be installed and in the path.
\nThe compiler package now includes build tool plugins for Grunt and Gulp.
\nnpm install --save google-closure-compiler\nThe compiler has a large number of flags. The best documentation for the flags can be found by running the --help command of the compiler.jar found inside the node_modules/google-closure-compiler folder:
java -jar compiler.jar --help\nBoth the grunt and gulp tasks take options objects. The option parameters map directly to the compiler flags without the leading -- characters.
Values are either strings or booleans. Options which have multiple values can be arrays.
\n{\n js: ['/file-one.js', '/file-two.js'],\n compilation_level: 'ADVANCED',\n js_output_file: 'out.js',\n debug: true\n}\nFor advanced usages, the options may be specified as an array of strings. These values include the -- characters and are directly passed to the compiler in the order specified:
[\n '--js', '/file-one.js',\n '--js', '/file-two.js',\n '--compilation_level', 'ADVANCED',\n '--js_output_file', 'out.js',\n '--debug'\n]\nWhen an array of flags is passed, the input files should not be specified via the build tools, but rather as compilation flags directly.
\nSome shells (particularly windows) try to do expansion on globs rather than passing the string on to the compiler. To prevent this it is necessary to quote certain arguments:
\n{\n js: '"my/quoted/glob/**.js"',\n compilation_level: 'ADVANCED',\n js_output_file: 'out.js',\n debug: true\n}\nInclude the plugin in your Gruntfile.js:
require('google-closure-compiler').grunt(grunt);\n// The load-grunt-tasks plugin won’t automatically load closure-compiler\nTask targets, files and options may be specified according to the grunt Configuring tasks guide.
\nrequire('google-closure-compiler').grunt(grunt);\n\n// Project configuration. \ngrunt.initConfig({\n 'closure-compiler': {\n my_target: {\n files: {\n 'dest/output.min.js': ['src/js/**/*.js']\n },\n options: {\n compilation_level: 'SIMPLE',\n language_in: 'ECMASCRIPT5_STRICT',\n create_source_map: 'dest/output.min.js.map',\n output_wrapper: '(function(){\\n%output%\\n}).call(this)\\n//# sourceMappingURL=output.min.js.map'\n }\n }\n }\n});\nThe gulp plugin supports piping multiple files through the compiler.
\nOptions are a direct match to the compiler flags without the leading --.
var closureCompiler = require('google-closure-compiler').gulp();\n\ngulp.task('js-compile', function () {\n return gulp.src('./src/js/**/*.js', { base: './' })\n .pipe(closureCompiler({\n compilation_level: 'SIMPLE',\n warning_level: 'VERBOSE',\n language_in: 'ECMASCRIPT6_STRICT',\n language_out: 'ECMASCRIPT5_STRICT',\n output_wrapper: '(function(){\\n%output%\\n}).call(this)',\n js_output_file: 'output.min.js'\n }))\n .pipe(gulp.dest('./dist/js'));\n});\nSource:
\nCoffeeScript is a little language that compiles into JavaScript. It is an attempt to expose the good parts of JavaScript in a simple way and friendly syntax, the golden rule being: “It’s just JavaScript”.
\nThe code compiles one-to-one into the equivalent JavaScript, and there is no interpretation at runtime. The compiled output is readable and pretty-printed, will work in every JavaScript runtime, and tends to run as fast or faster than the equivalent handwritten JavaScript.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/COFFEESCRIPT.md" }, { "name": "CommonJS", "description": "a project with the goal of specifying an ecosystem for JavaScript outside the browser (for example, on the server or for native desktop applications)", "markdown": "\n\n# CommonJS\n\n**CommonJS** is a project with the goal of specifying an ecosystem for JavaScript outside the browser (for example, on the server or for native desktop applications).\n\nServer side JavaScript has been around for a long time, and potentially offers some unique and interesting advantages over other languages because the same language is spoken by both client and server.\n\nUnfortunately, though, server side JavaScript is very fragmented. A script that accesses files can’t be used without modification on both rhino and [V8](/_glossary/V8.md). Spidermonkey and JavaScriptCore can’t both load in additional modules in the same way. A JavaScript web framework is very much tied to its interpreter and is often forced to create a bunch of APIs that Python, Ruby and Java programmers take for granted.\n\nThe goal for this project is to create a standard library that will ultimately allow web developers to choose among any number of web frameworks and tools and run that code on the platform that makes the most sense for their application.\n\n## History\n\nThe project was started by Mozilla engineer Kevin Dangoor in January 2009 and initially named **ServerJS**.\n\n> What I’m describing here is not a technical problem. It’s a matter of people getting together and making a decision to step forward and start building up something bigger and cooler together.\n> — Kevin Dangoor\n\nIn August 2009, the project was renamed **CommonJS** to show the broader applicability of the APIs. Specifications are created and approved in an open process. A specification is only considered final after it has been finished by multiple implementations. **CommonJS** is not affiliated with the [ECMA](/_glossary/ECMASCRIPT.md) International group TC39 working on ECMAScript, but some members of TC39 participate in the project.\n\nIn May 2013, Isaac Z. Schlueter, the author of [npm](/_glossary/NPM.md), the package manager for [Node.js](/_glossary/NODEJS.md), said **CommonJS** is being made obsolete by Node.js, and is avoided by the core Node.js developers.\n\n## Example usage\n\nAs an example, `foo.js` loads the module `circle.js` in the same directory.\n\nThe contents of `foo.js`:\n\n```js\nconst circle = require('./circle.js');\nconsole.log(`The area of a circle of radius 4 is ${circle.area(4)}`);\n```\n\nThe contents of `circle.js`:\n\n```js\nconst PI = Math.PI;\n\nexports.area = function (r) {\n return PI * r * r;\n};\n\nexports.circumference = function (r) {\n return 2 * PI * r;\n};\n```\n\nThe module `circle.js` has exported the functions `area(..)` and `circumference(..)`. To add functions and objects to the root of your module, you can add them to the special `exports` object.\n\nVariables local to the module will be private, as though the module was wrapped in a function. In this example the variable `PI` is private to `circle.js`.\n\nIf you want the root of your module’s export to be a function (such as a constructor) or if you want to export a complete object in one assignment instead of building it one property at a time, assign it to `module.exports` instead of `exports`.\n\nBelow, `bar.js` makes use of the square module, which exports a constructor:\n\n```js\nconst square = require('./square.js');\nvar mySquare = square(2);\nconsole.log(`The area of my square is ${mySquare.area()}`);\n```\n\nThe `square` module is defined in `square.js`:\n\n```js\n// Assigning to exports will not modify module, must use module.exports\nmodule.exports = function (width) {\n return {\n area: function () {\n return (width * width);\n }\n };\n}\n```\n\nThe module system is implemented in the `require('module')` module.\n\n*This section was taken from [Node.js documentation site](https://nodejs.org/docs/latest/api/modules.html).*\n", "html": "CommonJS is a project with the goal of specifying an ecosystem for JavaScript outside the browser (for example, on the server or for native desktop applications).
\nServer side JavaScript has been around for a long time, and potentially offers some unique and interesting advantages over other languages because the same language is spoken by both client and server.
\nUnfortunately, though, server side JavaScript is very fragmented. A script that accesses files can’t be used without modification on both rhino and V8. Spidermonkey and JavaScriptCore can’t both load in additional modules in the same way. A JavaScript web framework is very much tied to its interpreter and is often forced to create a bunch of APIs that Python, Ruby and Java programmers take for granted.
\nThe goal for this project is to create a standard library that will ultimately allow web developers to choose among any number of web frameworks and tools and run that code on the platform that makes the most sense for their application.
\nThe project was started by Mozilla engineer Kevin Dangoor in January 2009 and initially named ServerJS.
\n\n\nWhat I’m describing here is not a technical problem. It’s a matter of people getting together and making a decision to step forward and start building up something bigger and cooler together.\n— Kevin Dangoor
\n
In August 2009, the project was renamed CommonJS to show the broader applicability of the APIs. Specifications are created and approved in an open process. A specification is only considered final after it has been finished by multiple implementations. CommonJS is not affiliated with the ECMA International group TC39 working on ECMAScript, but some members of TC39 participate in the project.
\nIn May 2013, Isaac Z. Schlueter, the author of npm, the package manager for Node.js, said CommonJS is being made obsolete by Node.js, and is avoided by the core Node.js developers.
\nAs an example, foo.js loads the module circle.js in the same directory.
The contents of foo.js:
const circle = require('./circle.js');\nconsole.log(`The area of a circle of radius 4 is ${circle.area(4)}`);\nThe contents of circle.js:
const PI = Math.PI;\n\nexports.area = function (r) {\n return PI * r * r;\n};\n\nexports.circumference = function (r) {\n return 2 * PI * r;\n};\nThe module circle.js has exported the functions area(..) and circumference(..). To add functions and objects to the root of your module, you can add them to the special exports object.
Variables local to the module will be private, as though the module was wrapped in a function. In this example the variable PI is private to circle.js.
If you want the root of your module’s export to be a function (such as a constructor) or if you want to export a complete object in one assignment instead of building it one property at a time, assign it to module.exports instead of exports.
Below, bar.js makes use of the square module, which exports a constructor:
const square = require('./square.js');\nvar mySquare = square(2);\nconsole.log(`The area of my square is ${mySquare.area()}`);\nThe square module is defined in square.js:
// Assigning to exports will not modify module, must use module.exports\nmodule.exports = function (width) {\n return {\n area: function () {\n return (width * width);\n }\n };\n}\nThe module system is implemented in the require('module') module.
This section was taken from Node.js documentation site.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/COMMONJS.md" }, { "name": "CORS", "description": "a way for a server to make things accessible to pages hosted on other domains", "markdown": "\n\n# CORS\n\n[CORS](https://developer.mozilla.org/en-US/docs/Web/HTTP/Access_control_CORS) stands for Cross Origin Resource sharing. It’s a way for a server to allow pages hosted on other domains (technically other origins) to make http requests to it.\n\nA web page can usually embed images, scripts, video, audio, etc. from any location it wants. However, web fonts and [AJAX](/_glossary/AJAX.md) requests can usually only make requests to the same origin the web page is served from, because of the [same-origin policy](https://developer.mozilla.org/en-US/docs/Web/Security/Same-origin_policy). CORS allows a server to mark [resources](https://en.wikipedia.org/wiki/Web_resource) as shared with other origins, by sending an `Access-Control-Allow-Origin` [header](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers) in response to an [OPTIONS](http://www.w3.org/Protocols/rfc2616/rfc2616-sec9.html#sec9.2) request from the browser.\n\nFor information on how to set this up on your server, refer to [this document](http://enable-cors.org/server.html).\n", "html": "CORS stands for Cross Origin Resource sharing. It’s a way for a server to allow pages hosted on other domains (technically other origins) to make http requests to it.
\nA web page can usually embed images, scripts, video, audio, etc. from any location it wants. However, web fonts and AJAX requests can usually only make requests to the same origin the web page is served from, because of the same-origin policy. CORS allows a server to mark resources as shared with other origins, by sending an Access-Control-Allow-Origin header in response to an OPTIONS request from the browser.
For information on how to set this up on your server, refer to this document.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/CORS.md" }, { "name": "CouchDB", "description": "a NoSQL database with JavaScript as query language and HTTP as API", "markdown": "\n\n# CouchDB\n\n[Apache CouchDB](http://couchdb.apache.org/), commonly referred to as CouchDB, is an open source database that focuses on ease of use and on being “a database that completely embraces the web”.\n\nIt is a document-oriented NoSQL database that uses [JSON](/_glossary/JSON.md) to store data, JavaScript as its query language using MapReduce, and HTTP for an API.\n\nCouchDB was first released in 2005 and later became an Apache project in 2008.\n", "html": "Apache CouchDB, commonly referred to as CouchDB, is an open source database that focuses on ease of use and on being “a database that completely embraces the web”.
\nIt is a document-oriented NoSQL database that uses JSON to store data, JavaScript as its query language using MapReduce, and HTTP for an API.
\nCouchDB was first released in 2005 and later became an Apache project in 2008.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/COUCHDB.md" }, { "name": "Currying", "description": "the process to transform a function with multiple parameters into a chain of functions of one parameter", "markdown": "\n\n# Currying\n\nCurrying is the technique of translating the evaluation of a function that takes N arguments into evaluating a sequence of N functions, each with a single argument.\n\nThis process is done by calling the function with one parameter, and return a new function with the parameter already bound inside a [closure](/_glossary/CLOSURE.md).\n\nFor example, let’s say we have an `add` function that takes two parameters `a` and `b`:\n\n```js\n// The native function definition would be to have a and b as parameters:\nadd(3, 5)\n\n// After currying the function, we can then apply it like so:\ncurryAdd(3)(5)\n```\n\nThis is an interesting technique allowing to *partially call* a function, leaving the rest of the call for later.\n\nFor instance, with our previous `curryAdd` function:\n\n```js\nvar add3 = curryAdd(3);\nvar add10 = curryAdd(10);\n\n// Then we can call\nadd3(5) // => 8\nadd10(5) // => 15\n```\n\n[Lodash](/_glossary/LODASH.md), [Wu](https://fitzgen.github.io/wu.js/#curryable) and [Ramda](/_glossary/RAMDA.md) are 3 of the many libraries that provide currying.\n\n## Currying with Javascript Libraries\n\nMost Javascript libraries don't stick to this pure definition of currying, and instead mix in a bit of partial application. What this means is that they allow you to call the curried functions with more than one argument at a time. As you give it arguments, it will continue returning new curried functions until you've given it all the arguments it expects, at which point it will apply them to the function. It's really auto-curried partial application.\n\nThus, the following are equivalent:\n\n```js\nfoo(1)(2)(3)(4)(5);\nfoo(1, 2, 3, 4, 5);\nfoo(1)(2, 3, 4, 5);\nfoo(1, 2)(3)(4, 5);\n```\n\nIt's \"syntactic sugar\" that most libraries use, and for them the end result is the same as when you call `foo(1)(2)(3)(4)(5)`.\n", "html": "Currying is the technique of translating the evaluation of a function that takes N arguments into evaluating a sequence of N functions, each with a single argument.
\nThis process is done by calling the function with one parameter, and return a new function with the parameter already bound inside a closure.
\nFor example, let’s say we have an add function that takes two parameters a and b:
// The native function definition would be to have a and b as parameters:\nadd(3, 5)\n\n// After currying the function, we can then apply it like so:\ncurryAdd(3)(5)\nThis is an interesting technique allowing to partially call a function, leaving the rest of the call for later.
\nFor instance, with our previous curryAdd function:
var add3 = curryAdd(3);\nvar add10 = curryAdd(10);\n\n// Then we can call\nadd3(5) // => 8\nadd10(5) // => 15\nLodash, Wu and Ramda are 3 of the many libraries that provide currying.
\nMost Javascript libraries don't stick to this pure definition of currying, and instead mix in a bit of partial application. What this means is that they allow you to call the curried functions with more than one argument at a time. As you give it arguments, it will continue returning new curried functions until you've given it all the arguments it expects, at which point it will apply them to the function. It's really auto-curried partial application.
\nThus, the following are equivalent:
\nfoo(1)(2)(3)(4)(5);\nfoo(1, 2, 3, 4, 5);\nfoo(1)(2, 3, 4, 5);\nfoo(1, 2)(3)(4, 5);\nIt's "syntactic sugar" that most libraries use, and for them the end result is the same as when you call foo(1)(2)(3)(4)(5).
D3.js is a library for manipulating documents based on data. D3 helps bringing data to life using HTML, SVG, and CSS. Its emphasis on web standards gives the full capabilities of modern browsers without tying to a proprietary framework, combining powerful visualization components and a data-driven approach to DOM manipulation.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/D3JS.md" }, { "name": "Design Patterns", "description": "a general reusable solution to a commonly occurring problem within a given context in software design", "markdown": "\n\n# Design Patterns\n\nIn software engineering, a [design pattern](https://en.wikipedia.org/wiki/Software_design_pattern) is a general reusable solution to a commonly occurring problem within a given context in software design. A design pattern is not a finished design that can be transformed directly into source or machine code. It is a description or template for how to solve a problem that can be used in many different situations. Patterns are formalized best practices that the programmer can use to solve common problems when designing an application or system. Object-oriented design patterns typically show relationships and interactions between classes or objects, without specifying the final application classes or objects that are involved. Patterns that imply mutable state may be unsuited for functional programming languages, some patterns can be rendered unnecessary in languages that have built-in support for solving the problem they are trying to solve, and object-oriented patterns are not necessarily suitable for non-object-oriented languages.\n\nDesign patterns may be viewed as a structured approach to computer programming intermediate between the levels of a programming paradigm and a concrete algorithm.\n\n## Types\n\nDesign patterns reside in the domain of modules and interconnections. At a higher level there are architectural patterns which are larger in scope, usually describing an overall pattern followed by an entire system.\n\nThere are many types of design patterns, for instance:\n\n- **Algorithm strategy patterns** addressing concerns related to high-level strategies describing how to exploit application characteristics on a computing platform.\n- **Computational design patterns** addressing concerns related to key computation identification.\n- **Execution patterns** which address issues related to lower-level support of application execution, including strategies for executing streams of tasks and for the definition of building blocks to support task synchronization.\n- **Implementation strategy patterns** addressing concerns related to implementing source code to support\n 1. program organization, and\n 2. the common data structures specific to parallel programming.\n- **Structural design patterns** addressing concerns related to global structures of applications being developed.\n\n## History\n\nPatterns originated as an architectural concept by [Christopher Alexander](https://en.wikipedia.org/wiki/Christopher_Alexander) (1977/79). In 1987, [Kent Beck](https://en.wikipedia.org/wiki/Kent_Beck) and [Ward Cunningham](https://en.wikipedia.org/wiki/Ward_Cunningham) began experimenting with the idea of applying patterns to programming – specifically pattern languages – and presented their results at the [OOPSLA](https://en.wikipedia.org/wiki/OOPSLA) conference that year. In the following years, Beck, Cunningham and others followed up on this work.\n\nDesign patterns gained popularity in computer science after the book [Design Patterns: Elements of Reusable Object-Oriented Software](https://en.wikipedia.org/wiki/Design_Patterns_(book)) was published in 1994 by the so-called “Gang of Four” (Gamma et al.), which is frequently abbreviated as “GoF”. That same year, the first Pattern Languages of Programming Conference was held and the following year, the Portland Pattern Repository was set up for documentation of design patterns. The scope of the term remains a matter of dispute. Notable books in the design pattern genre include:\n\n- [Gamma, Erich](https://en.wikipedia.org/wiki/Erich_Gamma); [Helm, Richard](https://en.wikipedia.org/wiki/Richard_Helm); [Johnson, Ralph](https://en.wikipedia.org/wiki/Ralph_Johnson_(computer_scientist)); [Vlissides, John](https://en.wikipedia.org/wiki/John_Vlissides) (1995). [Design Patterns: Elements of Reusable Object-Oriented Software](https://en.wikipedia.org/wiki/Design_Patterns_(book)). Addison-Wesley. ISBN 0-201-63361-2.\n- [Brinch Hansen, Per](https://en.wikipedia.org/wiki/Per_Brinch_Hansen) (1995). *Studies in Computational Science: Parallel Programming Paradigms.* Prentice Hall. ISBN 0-13-439324-4.\n- Buschmann, Frank; Meunier, Regine; Rohnert, Hans; Sommerlad, Peter (1996). *Pattern-Oriented Software Architecture, Volume 1: A System of Patterns.* John Wiley & Sons. ISBN 0-471-95869-7.\n- [Schmidt, Douglas C.](https://en.wikipedia.org/wiki/Douglas_C._Schmidt); Stal, Michael; Rohnert, Hans; Buschmann, Frank (2000). *Pattern-Oriented Software Architecture, Volume 2: Patterns for Concurrent and Networked Objects.* John Wiley & Sons. ISBN 0-471-60695-2.\n- [Fowler, Martin](https://en.wikipedia.org/wiki/Martin_Fowler) (2002). *Patterns of Enterprise Application Architecture.* Addison-Wesley. ISBN 978-0-321-12742-6.\n- Hohpe, Gregor; Woolf, Bobby (2003). [Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions.](https://en.wikipedia.org/wiki/Enterprise_Integration_Patterns) Addison-Wesley. ISBN 0-321-20068-3.\n- Freeman, Eric T; Robson, Elisabeth; Bates, Bert; [Sierra, Kathy](https://en.wikipedia.org/wiki/Kathy_Sierra) (2004). *Head First Design Patterns.* O’Reilly Media. ISBN 0-596-00712-4.\n\nAlthough design patterns have been applied practically for a long time, formalization of the concept of design patterns languished for several years.\n\n## Practice\n\nDesign patterns can speed up the development process by providing tested, proven development paradigms. Effective software design requires considering issues that may not become visible until later in the implementation. Reusing design patterns helps to prevent subtle issues that can cause major problems, and it also improves code readability for coders and architects who are familiar with the patterns.\n\nIn order to achieve flexibility, design patterns usually introduce additional levels of indirection, which in some cases may complicate the resulting designs and hurt application performance.\n\nBy definition, a pattern must be programmed anew into each application that uses it. Since some authors see this as a step backward from software reuse as provided by components, researchers have worked to turn patterns into components. Meyer and Arnout were able to provide full or partial componentization of two-thirds of the patterns they attempted.\n\nSoftware design techniques are difficult to apply to a broader range of problems. Design patterns provide general solutions, documented in a format that does not require specifics tied to a particular problem.\n\n## Classification and list\n\nDesign patterns were originally grouped into the categories: *creational patterns*, *structural patterns*, and *behavioral patterns*, and described using the concepts of delegation, aggregation, and consultation. For further background on object-oriented design, see coupling and cohesion, inheritance, interface, and polymorphism. Another classification has also introduced the notion of architectural design pattern that may be applied at the architecture level of the software such as the Model–View–Controller pattern.\n\n### Creational patterns\n\n| Name | Description |\n| --- | --- |\n| [Abstract factory](https://en.wikipedia.org/wiki/Abstract_factory_pattern) | Provide an interface for creating families of related or dependent objects without specifying their concrete classes. |\n| [Builder](https://en.wikipedia.org/wiki/Builder_pattern) | Separate the construction of a complex object from its representation, allowing the same construction process to create various representations. |\n| [Factory method](/_glossary/FACTORY_PATTERN.md) | Define an interface for creating a single object, but let subclasses decide which class to instantiate. Factory Method lets a class defer instantiation to subclasses (dependency injection). |\n| [Lazy initialization](https://en.wikipedia.org/wiki/Lazy_initialization) | Tactic of delaying the creation of an object, the calculation of a value, or some other expensive process until the first time it is needed. This pattern appears in the GoF catalog as “virtual proxy”, an implementation strategy for the Proxy pattern. |\n| [Multiton](https://en.wikipedia.org/wiki/Multiton_pattern) | Ensure a class has only named instances, and provide a global point of access to them. |\n| [Object pool](https://en.wikipedia.org/wiki/Object_pool_pattern) | Avoid expensive acquisition and release of resources by recycling objects that are no longer in use. Can be considered a generalisation of connection pool and thread pool patterns. |\n| [Prototype](/_glossary/PROTOTYPE_PATTERN.md) | Specify the kinds of objects to create using a prototypical instance, and create new objects by copying this prototype. |\n| [Resource acquisition is initialization](https://en.wikipedia.org/wiki/Resource_Acquisition_Is_Initialization) | Ensure that resources are properly released by tying them to the lifespan of suitable objects. |\n| [Singleton](/_glossary/SINGLETON_PATTERN.md) | Ensure a class has only one instance, and provide a global point of access to it. |\n\n### Structural patterns\n\n| Name | Description |\n| --- | --- |\n| [Adapter](https://en.wikipedia.org/wiki/Adapter_pattern) or Wrapper or Translator | Convert the interface of a class into another interface clients expect. An adapter lets classes work together that could not otherwise because of incompatible interfaces. The enterprise integration pattern equivalent is the translator. |\n| [Bridge](https://en.wikipedia.org/wiki/Bridge_pattern) | Decouple an abstraction from its implementation allowing the two to vary independently. |\n| [Composite](https://en.wikipedia.org/wiki/Composite_pattern) | \tCompose objects into tree structures to represent part-whole hierarchies. Composite lets clients treat individual objects and compositions of objects uniformly. |\n| [Decorator](https://en.wikipedia.org/wiki/Decorator_pattern) | \tAttach additional responsibilities to an object dynamically keeping the same interface. Decorators provide a flexible alternative to subclassing for extending functionality. |\n| [Facade](/_glossary/FACADE_PATTERN.md) | Provide a unified interface to a set of interfaces in a subsystem. Facade defines a higher-level interface that makes the subsystem easier to use. |\n| [Flyweight](https://en.wikipedia.org/wiki/Flyweight_pattern) | Use sharing to support large numbers of similar objects efficiently. |\n| [Front controller](https://en.wikipedia.org/wiki/Front_controller) | The pattern relates to the design of Web applications. It provides a centralized entry point for handling requests. |\n| [Marker](https://en.wikipedia.org/wiki/Marker_interface_pattern) | Empty interface to associate metadata with a class. |\n| [Module](/_glossary/MODULE_PATTERN.md) | \tGroup several related elements, such as classes, singletons, methods, globally used, into a single conceptual entity. |\n| [Proxy](https://en.wikipedia.org/wiki/Proxy_pattern) | Provide a surrogate or placeholder for another object to control access to it. |\n| [Twin](https://en.wikipedia.org/wiki/Twin_pattern) | Twin allows modeling of multiple inheritance in programming languages that do not support this feature. |\n\n### Behavioural patterns\n\n| Name | Description |\n| --- | --- |\n| [Blackboard](https://en.wikipedia.org/wiki/Blackboard_design_pattern) | Artificial intelligence pattern for combining disparate sources of data (see blackboard system) |\n| [Chain of responsibility](https://en.wikipedia.org/wiki/Chain_of_responsibility_pattern) | Avoid coupling the sender of a request to its receiver by giving more than one object a chance to handle the request. Chain the receiving objects and pass the request along the chain until an object handles it. |\n| [Command](https://en.wikipedia.org/wiki/Command_pattern) | Encapsulate a request as an object, thereby letting you parameterize clients with different requests, queue or log requests, and support undoable operations. |\n| [Interpreter](https://en.wikipedia.org/wiki/Interpreter_pattern) | Given a language, define a representation for its grammar along with an interpreter that uses the representation to interpret sentences in the language. |\n| [Iterator](https://en.wikipedia.org/wiki/Iterator_pattern) | Provide a way to access the elements of an aggregate object sequentially without exposing its underlying representation. |\n| [Mediator](/_glossary/MEDIATOR_PATTERN.md) | Define an object that encapsulates how a set of objects interact. Mediator promotes loose coupling by keeping objects from referring to each other explicitly, and it lets you vary their interaction independently. |\n| [Memento](https://en.wikipedia.org/wiki/Memento_pattern) | Without violating encapsulation, capture and externalize an object’s internal state allowing the object to be restored to this state later. |\n| [Null object](https://en.wikipedia.org/wiki/Null_Object_pattern) | Avoid null references by providing a default object. |\n| [Observer](/_glossary/OBSERVER_PATTERN.md) or [Publish/subscribe](https://en.wikipedia.org/wiki/Publish/subscribe) | Define a one-to-many dependency between objects where a state change in one object results in all its dependents being notified and updated automatically. |\n| [Servant](https://en.wikipedia.org/wiki/Design_pattern_Servant) | Define common functionality for a group of classes. |\n| [Specification](https://en.wikipedia.org/wiki/Specification_pattern) | Recombinable business logic in a Boolean fashion. |\n| [State](https://en.wikipedia.org/wiki/State_pattern) | Allow an object to alter its behavior when its internal state changes. The object will appear to change its class. |\n| [Strategy](https://en.wikipedia.org/wiki/Strategy_pattern) | Define a family of algorithms, encapsulate each one, and make them interchangeable. Strategy lets the algorithm vary independently from clients that use it. |\n| [Template method](https://en.wikipedia.org/wiki/Template_method_pattern) | Define the skeleton of an algorithm in an operation, deferring some steps to subclasses. Template method lets subclasses redefine certain steps of an algorithm without changing the algorithm’s structure. |\n| [Visitor](https://en.wikipedia.org/wiki/Visitor_pattern) | Represent an operation to be performed on the elements of an object structure. Visitor lets you define a new operation without changing the classes of the elements on which it operates. |\n\n### Concurrency patterns\n\n| Name | Description |\n| --- | --- |\n| [Active Object](https://en.wikipedia.org/wiki/Active_object) | Decouples method execution from method invocation that reside in their own thread of control. The goal is to introduce concurrency, by using asynchronous method invocation and a scheduler for handling requests. |\n| [Balking](https://en.wikipedia.org/wiki/Balking_pattern) | Only execute an action on an object when the object is in a particular state. |\n| [Binding properties](https://en.wikipedia.org/wiki/Binding_properties_pattern) | Combining multiple observers to force properties in different objects to be synchronized or coordinated in some way. |\n| [Block chain](https://en.wikipedia.org/wiki/Block_chain_(database)) | Decentralized way to store data and agree on ways of processing it in a Merkle tree, optionally using Digital signature for any individual contributions. |\n| [Double-checked locking](https://en.wikipedia.org/wiki/Double_checked_locking_pattern) | Reduce the overhead of acquiring a lock by first testing the locking criterion (the “lock hint”) in an unsafe manner; only if that succeeds does the actual locking logic proceed. Can be unsafe when implemented in some language/hardware combinations. It can therefore sometimes be considered an anti-pattern. |\n| [Event-based asynchronous](https://en.wikipedia.org/wiki/Event-Based_Asynchronous_Pattern) | Addresses problems with the asynchronous pattern that occur in multithreaded programs. |\n| [Guarded suspension](https://en.wikipedia.org/wiki/Guarded_suspension) | \tManages operations that require both a lock to be acquired and a precondition to be satisfied before the operation can be executed. |\n| [Join](https://en.wikipedia.org/wiki/Join-pattern) | Join-pattern provides a way to write concurrent, parallel and distributed programs by message passing. Compared to the use of threads and locks, this is a high-level programming model. |\n| [Lock](https://en.wikipedia.org/wiki/Lock_(computer_science)) | One thread puts a “lock” on a resource, preventing other threads from accessing or modifying it. |\n| [Messaging design pattern (MDP)](https://en.wikipedia.org/wiki/Messaging_pattern) | Allows the interchange of information (i.e. messages) between components and applications. |\n| [Monitor object](https://en.wikipedia.org/wiki/Monitor_(synchronization)) | \tAn object whose methods are subject to mutual exclusion, thus preventing multiple objects from erroneously trying to use it at the same time. |\n| [Reactor](https://en.wikipedia.org/wiki/Reactor_pattern) | A reactor object provides an asynchronous interface to resources that must be handled synchronously. |\n| [Read-write lock](https://en.wikipedia.org/wiki/Read/write_lock_pattern) | Allows concurrent read access to an object, but requires exclusive access for write operations. |\n| [Scheduler](https://en.wikipedia.org/wiki/Scheduler_pattern) | Explicitly control when threads may execute single-threaded code. |\n| [Thread pool](https://en.wikipedia.org/wiki/Thread_pool_pattern) | \tA number of threads are created to perform a number of tasks, which are usually organized in a queue. Typically, there are many more tasks than threads. Can be considered a special case of the object pool pattern. |\n| [Thread-specific storage](https://en.wikipedia.org/wiki/Thread-Specific_Storage) | Static or “global” memory local to a thread. |\n\n## Documentation\n\nThe documentation for a design pattern describes the context in which the pattern is used, the forces within the context that the pattern seeks to resolve, and the suggested solution. There is no single, standard format for documenting design patterns. Rather, a variety of different formats have been used by different pattern authors. However, according to Martin Fowler, certain pattern forms have become more well-known than others, and consequently become common starting points for new pattern-writing efforts. One example of a commonly used documentation format is the one used by Erich Gamma, Richard Helm, Ralph Johnson and John Vlissides (collectively known as the “Gang of Four”, or GoF for short) in their book Design Patterns. It contains the following sections:\n\n- **Pattern Name and Classification**: A descriptive and unique name that helps in identifying and referring to the pattern.\n- **Intent**: A description of the goal behind the pattern and the reason for using it.\n- **Also Known As**: Other names for the pattern.\n- **Motivation (Forces)**: A scenario consisting of a problem and a context in which this pattern can be used.\n- **Applicability**: Situations in which this pattern is usable; the context for the pattern.\n- **Structure**: A graphical representation of the pattern. Class diagrams and Interaction diagrams may be used for this purpose.\n- **Participants**: A listing of the classes and objects used in the pattern and their roles in the design.\n- **Collaboration**: A description of how classes and objects used in the pattern interact with each other.\n- **Consequences**: A description of the results, side effects, and trade offs caused by using the pattern.\n- **Implementation**: A description of an implementation of the pattern; the solution part of the pattern.\n- **Sample Code**: An illustration of how the pattern can be used in a programming language.\n- **Known Uses**: Examples of real usages of the pattern.\n- **Related Patterns**: Other patterns that have some relationship with the pattern; discussion of the differences between the pattern and similar patterns.\n\n----------\n\n*Source:*\n- [Software design pattern](https://en.wikipedia.org/wiki/Software_design_pattern)*. From Wikipedia, the free encyclopedia.*\n", "html": "In software engineering, a design pattern is a general reusable solution to a commonly occurring problem within a given context in software design. A design pattern is not a finished design that can be transformed directly into source or machine code. It is a description or template for how to solve a problem that can be used in many different situations. Patterns are formalized best practices that the programmer can use to solve common problems when designing an application or system. Object-oriented design patterns typically show relationships and interactions between classes or objects, without specifying the final application classes or objects that are involved. Patterns that imply mutable state may be unsuited for functional programming languages, some patterns can be rendered unnecessary in languages that have built-in support for solving the problem they are trying to solve, and object-oriented patterns are not necessarily suitable for non-object-oriented languages.
\nDesign patterns may be viewed as a structured approach to computer programming intermediate between the levels of a programming paradigm and a concrete algorithm.
\nDesign patterns reside in the domain of modules and interconnections. At a higher level there are architectural patterns which are larger in scope, usually describing an overall pattern followed by an entire system.
\nThere are many types of design patterns, for instance:
\nPatterns originated as an architectural concept by Christopher Alexander (1977/79). In 1987, Kent Beck and Ward Cunningham began experimenting with the idea of applying patterns to programming – specifically pattern languages – and presented their results at the OOPSLA conference that year. In the following years, Beck, Cunningham and others followed up on this work.
\nDesign patterns gained popularity in computer science after the book Design Patterns: Elements of Reusable Object-Oriented Software) was published in 1994 by the so-called “Gang of Four” (Gamma et al.), which is frequently abbreviated as “GoF”. That same year, the first Pattern Languages of Programming Conference was held and the following year, the Portland Pattern Repository was set up for documentation of design patterns. The scope of the term remains a matter of dispute. Notable books in the design pattern genre include:
\nAlthough design patterns have been applied practically for a long time, formalization of the concept of design patterns languished for several years.
\nDesign patterns can speed up the development process by providing tested, proven development paradigms. Effective software design requires considering issues that may not become visible until later in the implementation. Reusing design patterns helps to prevent subtle issues that can cause major problems, and it also improves code readability for coders and architects who are familiar with the patterns.
\nIn order to achieve flexibility, design patterns usually introduce additional levels of indirection, which in some cases may complicate the resulting designs and hurt application performance.
\nBy definition, a pattern must be programmed anew into each application that uses it. Since some authors see this as a step backward from software reuse as provided by components, researchers have worked to turn patterns into components. Meyer and Arnout were able to provide full or partial componentization of two-thirds of the patterns they attempted.
\nSoftware design techniques are difficult to apply to a broader range of problems. Design patterns provide general solutions, documented in a format that does not require specifics tied to a particular problem.
\nDesign patterns were originally grouped into the categories: creational patterns, structural patterns, and behavioral patterns, and described using the concepts of delegation, aggregation, and consultation. For further background on object-oriented design, see coupling and cohesion, inheritance, interface, and polymorphism. Another classification has also introduced the notion of architectural design pattern that may be applied at the architecture level of the software such as the Model–View–Controller pattern.
\n| Name | \nDescription | \n
|---|---|
| Abstract factory | \nProvide an interface for creating families of related or dependent objects without specifying their concrete classes. | \n
| Builder | \nSeparate the construction of a complex object from its representation, allowing the same construction process to create various representations. | \n
| Factory method | \nDefine an interface for creating a single object, but let subclasses decide which class to instantiate. Factory Method lets a class defer instantiation to subclasses (dependency injection). | \n
| Lazy initialization | \nTactic of delaying the creation of an object, the calculation of a value, or some other expensive process until the first time it is needed. This pattern appears in the GoF catalog as “virtual proxy”, an implementation strategy for the Proxy pattern. | \n
| Multiton | \nEnsure a class has only named instances, and provide a global point of access to them. | \n
| Object pool | \nAvoid expensive acquisition and release of resources by recycling objects that are no longer in use. Can be considered a generalisation of connection pool and thread pool patterns. | \n
| Prototype | \nSpecify the kinds of objects to create using a prototypical instance, and create new objects by copying this prototype. | \n
| Resource acquisition is initialization | \nEnsure that resources are properly released by tying them to the lifespan of suitable objects. | \n
| Singleton | \nEnsure a class has only one instance, and provide a global point of access to it. | \n
| Name | \nDescription | \n
|---|---|
| Adapter or Wrapper or Translator | \nConvert the interface of a class into another interface clients expect. An adapter lets classes work together that could not otherwise because of incompatible interfaces. The enterprise integration pattern equivalent is the translator. | \n
| Bridge | \nDecouple an abstraction from its implementation allowing the two to vary independently. | \n
| Composite | \nCompose objects into tree structures to represent part-whole hierarchies. Composite lets clients treat individual objects and compositions of objects uniformly. | \n
| Decorator | \nAttach additional responsibilities to an object dynamically keeping the same interface. Decorators provide a flexible alternative to subclassing for extending functionality. | \n
| Facade | \nProvide a unified interface to a set of interfaces in a subsystem. Facade defines a higher-level interface that makes the subsystem easier to use. | \n
| Flyweight | \nUse sharing to support large numbers of similar objects efficiently. | \n
| Front controller | \nThe pattern relates to the design of Web applications. It provides a centralized entry point for handling requests. | \n
| Marker | \nEmpty interface to associate metadata with a class. | \n
| Module | \nGroup several related elements, such as classes, singletons, methods, globally used, into a single conceptual entity. | \n
| Proxy | \nProvide a surrogate or placeholder for another object to control access to it. | \n
| Twin | \nTwin allows modeling of multiple inheritance in programming languages that do not support this feature. | \n
| Name | \nDescription | \n
|---|---|
| Blackboard | \nArtificial intelligence pattern for combining disparate sources of data (see blackboard system) | \n
| Chain of responsibility | \nAvoid coupling the sender of a request to its receiver by giving more than one object a chance to handle the request. Chain the receiving objects and pass the request along the chain until an object handles it. | \n
| Command | \nEncapsulate a request as an object, thereby letting you parameterize clients with different requests, queue or log requests, and support undoable operations. | \n
| Interpreter | \nGiven a language, define a representation for its grammar along with an interpreter that uses the representation to interpret sentences in the language. | \n
| Iterator | \nProvide a way to access the elements of an aggregate object sequentially without exposing its underlying representation. | \n
| Mediator | \nDefine an object that encapsulates how a set of objects interact. Mediator promotes loose coupling by keeping objects from referring to each other explicitly, and it lets you vary their interaction independently. | \n
| Memento | \nWithout violating encapsulation, capture and externalize an object’s internal state allowing the object to be restored to this state later. | \n
| Null object | \nAvoid null references by providing a default object. | \n
| Observer or Publish/subscribe | \nDefine a one-to-many dependency between objects where a state change in one object results in all its dependents being notified and updated automatically. | \n
| Servant | \nDefine common functionality for a group of classes. | \n
| Specification | \nRecombinable business logic in a Boolean fashion. | \n
| State | \nAllow an object to alter its behavior when its internal state changes. The object will appear to change its class. | \n
| Strategy | \nDefine a family of algorithms, encapsulate each one, and make them interchangeable. Strategy lets the algorithm vary independently from clients that use it. | \n
| Template method | \nDefine the skeleton of an algorithm in an operation, deferring some steps to subclasses. Template method lets subclasses redefine certain steps of an algorithm without changing the algorithm’s structure. | \n
| Visitor | \nRepresent an operation to be performed on the elements of an object structure. Visitor lets you define a new operation without changing the classes of the elements on which it operates. | \n
| Name | \nDescription | \n
|---|---|
| Active Object | \nDecouples method execution from method invocation that reside in their own thread of control. The goal is to introduce concurrency, by using asynchronous method invocation and a scheduler for handling requests. | \n
| Balking | \nOnly execute an action on an object when the object is in a particular state. | \n
| Binding properties | \nCombining multiple observers to force properties in different objects to be synchronized or coordinated in some way. | \n
| Block chain) | \nDecentralized way to store data and agree on ways of processing it in a Merkle tree, optionally using Digital signature for any individual contributions. | \n
| Double-checked locking | \nReduce the overhead of acquiring a lock by first testing the locking criterion (the “lock hint”) in an unsafe manner; only if that succeeds does the actual locking logic proceed. Can be unsafe when implemented in some language/hardware combinations. It can therefore sometimes be considered an anti-pattern. | \n
| Event-based asynchronous | \nAddresses problems with the asynchronous pattern that occur in multithreaded programs. | \n
| Guarded suspension | \nManages operations that require both a lock to be acquired and a precondition to be satisfied before the operation can be executed. | \n
| Join | \nJoin-pattern provides a way to write concurrent, parallel and distributed programs by message passing. Compared to the use of threads and locks, this is a high-level programming model. | \n
| Lock) | \nOne thread puts a “lock” on a resource, preventing other threads from accessing or modifying it. | \n
| Messaging design pattern (MDP) | \nAllows the interchange of information (i.e. messages) between components and applications. | \n
| Monitor object) | \nAn object whose methods are subject to mutual exclusion, thus preventing multiple objects from erroneously trying to use it at the same time. | \n
| Reactor | \nA reactor object provides an asynchronous interface to resources that must be handled synchronously. | \n
| Read-write lock | \nAllows concurrent read access to an object, but requires exclusive access for write operations. | \n
| Scheduler | \nExplicitly control when threads may execute single-threaded code. | \n
| Thread pool | \nA number of threads are created to perform a number of tasks, which are usually organized in a queue. Typically, there are many more tasks than threads. Can be considered a special case of the object pool pattern. | \n
| Thread-specific storage | \nStatic or “global” memory local to a thread. | \n
The documentation for a design pattern describes the context in which the pattern is used, the forces within the context that the pattern seeks to resolve, and the suggested solution. There is no single, standard format for documenting design patterns. Rather, a variety of different formats have been used by different pattern authors. However, according to Martin Fowler, certain pattern forms have become more well-known than others, and consequently become common starting points for new pattern-writing efforts. One example of a commonly used documentation format is the one used by Erich Gamma, Richard Helm, Ralph Johnson and John Vlissides (collectively known as the “Gang of Four”, or GoF for short) in their book Design Patterns. It contains the following sections:
\nSource:
\nDOM (for Document Object Model) is a platform- and language-neutral interface that will allow programs and scripts to dynamically access and update the content, structure and style of documents. The document can be further processed and the results of that processing can be incorporated back into the presented page. This is an overview of DOM-related materials here at W3C and around the web.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/DOM.md" }, { "name": "ECMAScript (ES)", "description": "the standardized specification of the scripting language used by JavaScript", "markdown": "\n\n# ECMAScript (ES)\n\n[ECMAScript](http://www.ecmascript.org/) (shortened as *ES*) is the standardized specification of the scripting language used by JavaScript, as well as less known languages JScript and ActionScript.\n\nThe versioning convention of ECMAScript has been the subject of hot debates. We often refer to ES5 (understood by most browsers), ES6 (the future of JavaScript) and even ES7 (the far future of JavaScript), but the official appellation for ES6 would actually be ES2015. The intention is to publish a version of the specification every year, making the language evolve quicker than ever. Still, most developers use ES5 and ES6 terms.\n", "html": "ECMAScript (shortened as ES) is the standardized specification of the scripting language used by JavaScript, as well as less known languages JScript and ActionScript.
\nThe versioning convention of ECMAScript has been the subject of hot debates. We often refer to ES5 (understood by most browsers), ES6 (the future of JavaScript) and even ES7 (the far future of JavaScript), but the official appellation for ES6 would actually be ES2015. The intention is to publish a version of the specification every year, making the language evolve quicker than ever. Still, most developers use ES5 and ES6 terms.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/ECMASCRIPT.md" }, { "name": "Electron", "description": "a framework based on Node.js lets you write cross-platform desktop applications using JS, HTML and CSS", "markdown": "\n\n# Electron\n\n[Electron](https://github.com/atom/electron) is a framework lets you write cross-platform desktop applications using JavaScript, HTML and CSS. It is based on Node.js and Chromium and is used in the Atom editor.\n", "html": "Electron is a framework lets you write cross-platform desktop applications using JavaScript, HTML and CSS. It is based on Node.js and Chromium and is used in the Atom editor.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/ELECTRON.md" }, { "name": "Ember", "description": "an application framework based on the model-view-controller pattern", "markdown": "\n\n# Ember\n\n[Ember](http://emberjs.com/) is an application framework based on the model-view-controller pattern. By incorporating common patterns and idioms into the framework it aims to allow developers to create ambitious web applications quickly and easily. A side-effect of these abilities (either negative or positive depending upon the readers point of view) is that a certain conformity of naming and structure within those applications is expected.\n\nA key aim of the Ember project is that backward compatibility is an important feature of the framework so that applications may be built with Ember in the knowledge that future releases of the framework will not break those applications.\n\nEmber relies upon the following [core concepts](https://guides.emberjs.com/v2.1.0/getting-started/core-concepts/):\n\n - **Templates**: Ember.js templates use [handlebars](http://handlebarsjs.com/) style syntax and are used to integrate data with pre-written HTML.\n - **Models**: In Ember.js models allow the objects which the web application makes use of to be persisted.\n - **Components**: Components are used to define the behavior of the user interface in Ember.js. By combining a template and some javascript a component works to produce a representation which is useful to the web application user.\n - **Routes**: A route loads a component, a template and, optionally, some models. The resulting HTML is then rendered to the user agent.\n - **The Router**: Maps a URL to a given route.\n", "html": "Ember is an application framework based on the model-view-controller pattern. By incorporating common patterns and idioms into the framework it aims to allow developers to create ambitious web applications quickly and easily. A side-effect of these abilities (either negative or positive depending upon the readers point of view) is that a certain conformity of naming and structure within those applications is expected.
\nA key aim of the Ember project is that backward compatibility is an important feature of the framework so that applications may be built with Ember in the knowledge that future releases of the framework will not break those applications.
\nEmber relies upon the following core concepts:
\nEnzyme is a JavaScript Testing utility for React developed by AirBnB that makes it easier to assert, manipulate, and traverse React components’ output.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/ENZYME.md" }, { "name": "ESLint", "description": "a JavaScript code linter", "markdown": "\n\n# ESLint\n\n[ESLint](http://eslint.org/) is the most recent out of the JavaScript linters out there. It was designed to be easily extensible, comes with a large number of custom rules, and is easy to install more in the form of plugins. It gives concise output, but includes the rule name by default so you always know which rules are causing the error messages.\n\nThere are two very popular ready to use configuration for ESLint: [standard](https://github.com/feross/standard) (no semicolons) and [semistandard](https://github.com/Flet/semistandard).\n", "html": "ESLint is the most recent out of the JavaScript linters out there. It was designed to be easily extensible, comes with a large number of custom rules, and is easy to install more in the form of plugins. It gives concise output, but includes the rule name by default so you always know which rules are causing the error messages.
\nThere are two very popular ready to use configuration for ESLint: standard (no semicolons) and semistandard.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/ESLINT.md" }, { "name": "Express", "description": "a fast, un-opinionated, minimalist web framework for Node.js", "markdown": "\n\n# Express\n\n[Express](http://expressjs.com/en/index.html) is a fast, un-opinionated, minimalist web framework for [Node.js](/_glossary/NODEJS.md). Express provides a thin layer of fundamental web application features, without obscuring Node.js features that developers already know and like. The myriad of HTTP utility methods and middleware provided by Express makes creating a robust API quick and easy.\n", "html": "Express is a fast, un-opinionated, minimalist web framework for Node.js. Express provides a thin layer of fundamental web application features, without obscuring Node.js features that developers already know and like. The myriad of HTTP utility methods and middleware provided by Express makes creating a robust API quick and easy.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/EXPRESS.md" }, { "name": "Ext JS", "description": "a pure JavaScript application framework for building interactive cross platform web applications", "markdown": "\n\n# Ext JS\n\nThe most comprehensive JavaScript framework for building feature-rich cross-platform web applications targeting desktop, tablets, and smartphones. **Ext JS** leverages HTML5 features on modern browsers while maintaining compatibility and functionality for legacy browsers.\n\n## Create feature-rich HTML5 applications using JavaScript\n\n[Sencha Ext JS](https://www.sencha.com/products/extjs/) is the most comprehensive MVC/MVVM JavaScript framework for building feature-rich cross-platform web applications targeting desktops, tablets, and smartphones. Ext JS leverages HTML5 features on modern browsers while maintaining compatibility and functionality for legacy browsers.\n\nExt JS features hundreds of high-performance UI widgets that are meticulously designed to fit the needs of the simplest as well as the most complex web applications. Ext JS templates and layout manager give you full control over your display irrespective of devices and screen sizes. An advanced charting package allows you to visualize large quantities of data. The framework includes a robust data package that can consume data from any backend data source. Ext JS also offers several out-of-the-box themes, and complete theming support that lets you build applications that reflect your brand. It also includes an accessibility package (ARIA) to help with Section 508 compliance.\n\n### High-Performance Customizable UI Widgets\n\nSencha Ext JS provides the industry’s most comprehensive collection of high-performance, customizable UI widgets. These widgets include HTML5 grids, trees, lists, forms, menus, toolbars, panels, windows, and much more. If you don’t find a widget you are looking for, hundreds of user extensions are available from the Sencha community.\n\n### Backend Agnostic Data Package\n\nThe robust data package included in Sencha Ext JS decouples the UI widgets from the data layer. The data package allows client-side collections of data using highly functional models that offer features such as sorting and filtering. The data package is protocol agnostic, and can consume data from any backend source. It comes with session management capabilities that allow several client-side operations, minimizing round-trips to the server.\n\n### Layout Manager and Responsive Configs\n\nSencha Ext JS includes a flexible layout manager to help organize the display of data and content across multiple browsers, devices, and screen sizes. It helps you to control the display of components, even for the most complex user interfaces. Ext JS also provides a responsive config system that allows application components to adapt to specific device orientation (landscape or portrait) or available browser window size.\n\n### Advanced Charting Package\n\nThe Sencha Ext JS charting package allows you to visually represent data with a broad range of chart types — including line, bar, and pie charts. The charts use surfaces and sprites developed with a drawing package implemented using SVG, VML, and Canvas technologies. Browser variations are handled automatically so that the charts always display correctly. Ext JS charts also support touch gestures on mobile devices, thereby providing enhanced interactive features to the charts such as pan, zoom, and pinch.\n\n### Easily Customizable Themes\n\nSencha Ext JS widgets are available in multiple out-of-the-box themes such as Classic, Neptune, and Crisp. The themes are customizable to reflect a specific brand identity. Sencha Cmd exposes hundreds of variables used by Ext JS themes, which can be altered to design custom themes. A visual theme builder is also available in Sencha Architect that lets you customize the themes via a WYSIWYG editor.\n\n### Accessibility Package (ARIA) for Section 508 compliance\n\nSencha Ext JS ARIA Package makes it possible to add accessibility support to your applications by providing tools that developers need to achieve Section 508 Compliance. Using the ARIA package, developers can create apps that are usable for people who need assistive technologies such as screen readers to navigate the web.\n\n### App Templates\n\nA variety of application templates come pre-installed to kickstart your app, instead of starting from a blank canvas. Templates are editable and completely customizable, and you can even create your own templates and reuse them for future projects.\n", "html": "The most comprehensive JavaScript framework for building feature-rich cross-platform web applications targeting desktop, tablets, and smartphones. Ext JS leverages HTML5 features on modern browsers while maintaining compatibility and functionality for legacy browsers.
\nSencha Ext JS is the most comprehensive MVC/MVVM JavaScript framework for building feature-rich cross-platform web applications targeting desktops, tablets, and smartphones. Ext JS leverages HTML5 features on modern browsers while maintaining compatibility and functionality for legacy browsers.
\nExt JS features hundreds of high-performance UI widgets that are meticulously designed to fit the needs of the simplest as well as the most complex web applications. Ext JS templates and layout manager give you full control over your display irrespective of devices and screen sizes. An advanced charting package allows you to visualize large quantities of data. The framework includes a robust data package that can consume data from any backend data source. Ext JS also offers several out-of-the-box themes, and complete theming support that lets you build applications that reflect your brand. It also includes an accessibility package (ARIA) to help with Section 508 compliance.
\nSencha Ext JS provides the industry’s most comprehensive collection of high-performance, customizable UI widgets. These widgets include HTML5 grids, trees, lists, forms, menus, toolbars, panels, windows, and much more. If you don’t find a widget you are looking for, hundreds of user extensions are available from the Sencha community.
\nThe robust data package included in Sencha Ext JS decouples the UI widgets from the data layer. The data package allows client-side collections of data using highly functional models that offer features such as sorting and filtering. The data package is protocol agnostic, and can consume data from any backend source. It comes with session management capabilities that allow several client-side operations, minimizing round-trips to the server.
\nSencha Ext JS includes a flexible layout manager to help organize the display of data and content across multiple browsers, devices, and screen sizes. It helps you to control the display of components, even for the most complex user interfaces. Ext JS also provides a responsive config system that allows application components to adapt to specific device orientation (landscape or portrait) or available browser window size.
\nThe Sencha Ext JS charting package allows you to visually represent data with a broad range of chart types — including line, bar, and pie charts. The charts use surfaces and sprites developed with a drawing package implemented using SVG, VML, and Canvas technologies. Browser variations are handled automatically so that the charts always display correctly. Ext JS charts also support touch gestures on mobile devices, thereby providing enhanced interactive features to the charts such as pan, zoom, and pinch.
\nSencha Ext JS widgets are available in multiple out-of-the-box themes such as Classic, Neptune, and Crisp. The themes are customizable to reflect a specific brand identity. Sencha Cmd exposes hundreds of variables used by Ext JS themes, which can be altered to design custom themes. A visual theme builder is also available in Sencha Architect that lets you customize the themes via a WYSIWYG editor.
\nSencha Ext JS ARIA Package makes it possible to add accessibility support to your applications by providing tools that developers need to achieve Section 508 Compliance. Using the ARIA package, developers can create apps that are usable for people who need assistive technologies such as screen readers to navigate the web.
\nA variety of application templates come pre-installed to kickstart your app, instead of starting from a blank canvas. Templates are editable and completely customizable, and you can even create your own templates and reuse them for future projects.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/EXTJS.md" }, { "name": "Facade Pattern", "description": "a software design pattern commonly used with object-oriented programming. The name is by analogy to an architectural facade", "markdown": "\n\n# Facade Pattern\n\nThe [Facade Pattern](https://en.wikipedia.org/wiki/Facade_pattern) (**or façade pattern**) is a software design pattern commonly used with *object-oriented programming*. The name is by analogy to an architectural facade.\n\nA facade is an object that provides a simplified interface to a larger body of code, such as a class library. A facade can:\n\n- make a software library easier to use, understand and test, since the facade has convenient methods for common tasks;\n- make the library more readable, for the same reason;\n- reduce dependencies of outside code on the inner workings of a library, since most code uses the facade, thus allowing more flexibility in developing the system;\n- wrap a poorly designed collection of APIs with a single well-designed API.\n\nThe Facade design pattern is often used when a system is very complex or difficult to understand because the system has a large number of interdependent classes or its source code is unavailable. This pattern hides the complexities of the larger system and provides a simpler interface to the client. It typically involves a single wrapper class which contains a set of members required by client. These members access the system on behalf of the facade client and hide the implementation details.\n\n## Usage\n\nA Facade is used when an easier or simpler interface to an underlying object is desired. Alternatively, an [adapter](https://en.wikipedia.org/wiki/Adapter_pattern) can be used when the wrapper must respect a particular interface and must support polymorphic behavior. A [decorator](https://en.wikipedia.org/wiki/Decorator_pattern) makes it possible to add or alter behavior of an interface at run-time.\n\n| Pattern | Intent |\n|---|---|\n| Adapter | Converts one interface to another so that it matches what the client is expecting |\n| Decorator | Dynamically adds responsibility to the interface by wrapping the original code |\n| Facade | Provides a simplified interface |\n\nThe facade pattern is typically used when:\n\n- a simple interface is required to access a complex system;\n- the abstractions and implementations of a subsystem are tightly coupled;\n- need an entry point to each level of layered software; or\n- a system is very complex or difficult to understand.\n\n## Structure\n\n\n\n**Facade**: The facade class abstracts Packages 1, 2, and 3 from the rest of the application.\n**Clients**: The objects are using the Facade Pattern to access resources from the Packages.\n\n## Example\n\nThis is an abstract example of how a client (“you”) interacts with a facade (the “computer”) to a complex system (internal computer parts, like CPU and HardDrive).\n\n```js\n/* Complex parts */\n\nclass CPU {\n freeze() { /* code here */ }\n jump(position) { /* code here */ }\n execute() { /* code here */ }\n}\n\nclass Memory {\n load(position, data) { /* code here */ }\n}\n\nclass HardDrive {\n read(lba, size) { /* code here */ }\n}\n\n/* Facade */\n\nclass ComputerFacade {\n constructor() {\n this.processor = new CPU();\n this.ram = new Memory();\n this.hd = new HardDrive();\n }\n\n start() {\n this.processor.freeze();\n this.ram.load(this.BOOT_ADDRESS, this.hd.read(this.BOOT_SECTOR, this.SECTOR_SIZE));\n this.processor.jump(this.BOOT_ADDRESS);\n this.processor.execute();\n }\n}\n\n/* Client */\n\nlet computer = new ComputerFacade();\ncomputer.start();\n```\n\n*Source: [Facade pattern](https://en.wikipedia.org/wiki/Facade_pattern). Wikipedia®*\n", "html": "The Facade Pattern (or façade pattern) is a software design pattern commonly used with object-oriented programming. The name is by analogy to an architectural facade.
\nA facade is an object that provides a simplified interface to a larger body of code, such as a class library. A facade can:
\nThe Facade design pattern is often used when a system is very complex or difficult to understand because the system has a large number of interdependent classes or its source code is unavailable. This pattern hides the complexities of the larger system and provides a simpler interface to the client. It typically involves a single wrapper class which contains a set of members required by client. These members access the system on behalf of the facade client and hide the implementation details.
\nA Facade is used when an easier or simpler interface to an underlying object is desired. Alternatively, an adapter can be used when the wrapper must respect a particular interface and must support polymorphic behavior. A decorator makes it possible to add or alter behavior of an interface at run-time.
\n| Pattern | \nIntent | \n
|---|---|
| Adapter | \nConverts one interface to another so that it matches what the client is expecting | \n
| Decorator | \nDynamically adds responsibility to the interface by wrapping the original code | \n
| Facade | \nProvides a simplified interface | \n
The facade pattern is typically used when:
\n
Facade: The facade class abstracts Packages 1, 2, and 3 from the rest of the application.\nClients: The objects are using the Facade Pattern to access resources from the Packages.
\nThis is an abstract example of how a client (“you”) interacts with a facade (the “computer”) to a complex system (internal computer parts, like CPU and HardDrive).
\n/* Complex parts */\n\nclass CPU {\n freeze() { /* code here */ }\n jump(position) { /* code here */ }\n execute() { /* code here */ }\n}\n\nclass Memory {\n load(position, data) { /* code here */ }\n}\n\nclass HardDrive {\n read(lba, size) { /* code here */ }\n}\n\n/* Facade */\n\nclass ComputerFacade {\n constructor() {\n this.processor = new CPU();\n this.ram = new Memory();\n this.hd = new HardDrive();\n }\n\n start() {\n this.processor.freeze();\n this.ram.load(this.BOOT_ADDRESS, this.hd.read(this.BOOT_SECTOR, this.SECTOR_SIZE));\n this.processor.jump(this.BOOT_ADDRESS);\n this.processor.execute();\n }\n}\n\n/* Client */\n\nlet computer = new ComputerFacade();\ncomputer.start();\nSource: Facade pattern. Wikipedia®
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/FACADE_PATTERN.md" }, { "name": "Factory Pattern", "description": "a creational pattern that uses factory methods to deal with the problem of creating objects without having to specify the exact class of the object that will be created", "markdown": "\n\n# Factory Pattern\n\nIn class-based programming, the **factory method pattern** is a creational pattern that uses factory methods to deal with the problem of creating objects without having to specify the exact class of the object that will be created. This is done by creating objects by calling a factory method—either specified in an interface and implemented by child classes, or implemented in a base class and optionally overridden by derived classes—rather than by calling a constructor.\n\n## Definition\n\n> Define an interface for creating an object, but let subclasses decide which class to instantiate. The Factory method lets a class defer instantiation it uses to subclasses.\n> — [Gang Of Four](https://en.wikipedia.org/wiki/Gang_of_Four_(software))\n\nCreating an object often requires complex processes not appropriate to include within a composing object. The object’s creation may lead to a significant duplication of code, may require information not accessible to the composing object, may not provide a sufficient level of abstraction, or may otherwise not be part of the composing object’s concerns. The factory method design pattern handles these problems by defining a separate method for creating the objects, which subclasses can then override to specify the derived type of product that will be created.\n\nThe factory method pattern may rely on inheritance, as object creation is delegated to subclasses that implement the factory method to create objects.\n\n## Structure\n\n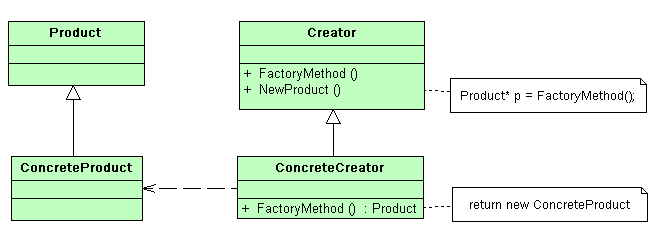\n\n- **Product**\n - it defines the interface of objects created by the abstract;\n- **ConcreteProduct**\n - implements the `Product`;\n- **Creator**\n - Ii declares the factory method that returns an object of type `Product`. It may also include the implementation of this method as “*default*”;\n - it can cause a factory method to create an object of type `Product`;\n- **ConcreteCreator**\n - it overrides the factory method so that he created and returns an object of class `ConcreteProduct`.\n\n## Example\n\n```js\nclass Product() {\n getName() {\n return null;\n }\n}\n\nclass ConcreteProductA extends Product {\n getName() {\n return 'ConcreteProductA';\n }\n}\n\nclass ConcreteProductB extends Product {\n getName() {\n return 'ConcreteProductB';\n }\n}\n\nclass Creator() {\n factoryMethod() {\n return null;\n }\n}\n\nclass ConcreteCreatorA extends Creator {\n factoryMethod() {\n return new ConcreteProductA();\n }\n}\n\nclass ConcreteCreatorB extends Creator {\n factoryMethod() {\n return new ConcreteProductB();\n }\n}\n\n// An array of creators\nlet creators = [new ConcreteCreatorA(), new ConcreteCreatorB()];\n\n// Iterate over creators and create products\nfor (let i = 0; i < creators.length; i++) {\n let product = creators[i].factoryMethod();\n console.log(product.getName());\n}\n```\n\n*Source: [Factory method pattern](https://en.wikipedia.org/wiki/Factory_method_pattern). Wikipedia®*\n", "html": "In class-based programming, the factory method pattern is a creational pattern that uses factory methods to deal with the problem of creating objects without having to specify the exact class of the object that will be created. This is done by creating objects by calling a factory method—either specified in an interface and implemented by child classes, or implemented in a base class and optionally overridden by derived classes—rather than by calling a constructor.
\n\n\nDefine an interface for creating an object, but let subclasses decide which class to instantiate. The Factory method lets a class defer instantiation it uses to subclasses.\n— Gang Of Four)
\n
Creating an object often requires complex processes not appropriate to include within a composing object. The object’s creation may lead to a significant duplication of code, may require information not accessible to the composing object, may not provide a sufficient level of abstraction, or may otherwise not be part of the composing object’s concerns. The factory method design pattern handles these problems by defining a separate method for creating the objects, which subclasses can then override to specify the derived type of product that will be created.
\nThe factory method pattern may rely on inheritance, as object creation is delegated to subclasses that implement the factory method to create objects.
\n
Product;Product. It may also include the implementation of this method as “default”;Product;ConcreteProduct.class Product() {\n getName() {\n return null;\n }\n}\n\nclass ConcreteProductA extends Product {\n getName() {\n return 'ConcreteProductA';\n }\n}\n\nclass ConcreteProductB extends Product {\n getName() {\n return 'ConcreteProductB';\n }\n}\n\nclass Creator() {\n factoryMethod() {\n return null;\n }\n}\n\nclass ConcreteCreatorA extends Creator {\n factoryMethod() {\n return new ConcreteProductA();\n }\n}\n\nclass ConcreteCreatorB extends Creator {\n factoryMethod() {\n return new ConcreteProductB();\n }\n}\n\n// An array of creators\nlet creators = [new ConcreteCreatorA(), new ConcreteCreatorB()];\n\n// Iterate over creators and create products\nfor (let i = 0; i < creators.length; i++) {\n let product = creators[i].factoryMethod();\n console.log(product.getName());\n}\nSource: Factory method pattern. Wikipedia®
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/FACTORY_PATTERN.md" }, { "name": "Falcor", "description": "a JavaScript library for efficient data fetching", "markdown": "\n\n# Falcor\n\n[Falcor](https://netflix.github.io/falcor/) is a JavaScript library for efficient data fetching.\n\n### One Model Everywhere\n\nFalcor lets you represent all your remote data sources as a single domain model via a virtual [JSON](/_glossary/JSON.md) graph. You code the same way no matter where the data is, whether in memory on the client or over the network on the server.\n\n### The Data is the API\n\nA JavaScript-like path syntax makes it easy to access as much or as little data as you want, when you want it. You retrieve your data using familiar JavaScript operations like get, set, and call. If you know your data, you know your API.\n\n### Bind to the Cloud\n\nFalcor automatically traverses references in your graph and makes requests as needed. Falcor transparently handles all network communications, opportunistically batching and de-duping requests.\n\n## Getting Started\n\nYou can check out a working example server for a Netflix-like application [here](http://github.com/netflix/falcor-express-demo) right now. Alternately you can go through this barebones tutorial in which we use the Falcor Router to create a Virtual JSON resource. In this tutorial we will use Falcor’s express middleware to serve the Virtual JSON resource on an application server at the URL /model.json. We will also host a static web page on the same server which retrieves data from the Virtual JSON resource.\n\n### Creating a Virtual JSON Resource\n\nIn this example we will use the Falcor Router to build a Virtual JSON resource on an app server and host it at `/model.json`. The JSON resource will contain the following contents:\n\n```json\n{\n \"greeting\": \"Hello World\"\n}\n```\n\nNormally Routers retrieve the data for their Virtual JSON resource from backend datastores or other web services on-demand. However in this simple tutorial the Router will simply return static data for a single key.\n\nFirst we create a folder for our application server.\n\n```sh\nmkdir falcor-app-server\ncd falcor-app-server\nnpm init\n```\n\nNow we install the falcor Router.\n\n```sh\nnpm install falcor-router --save\n```\n\nThen install express and falcor-express. Support for [restify](https://github.com/netflix/falcor-restify), and [Hapi](https://github.com/netflix/falcor-hapi) is also available.\n\n```sh\nnpm install express --save\nnpm install falcor-express --save\n```\n\nNow we create an `index.js` file with the following contents:\n\n```js\n// index.js\nvar falcorExpress = require('falcor-express');\nvar Router = require('falcor-router');\nvar express = require('express');\nvar app = express();\n\napp.use('/model.json', falcorExpress.dataSourceRoute(function (req, res) {\n // create a Virtual JSON resource with single key (“greeting”)\n return new Router([\n {\n // match a request for the key “greeting”\n route: 'greeting',\n // respond with a PathValue with the value of “Hello World”\n get: function () {\n return {\n path: ['greeting'],\n value: 'Hello World'\n };\n }\n }\n ]);\n}));\n\n// serve static files from current directory\napp.use(express.static(__dirname + '/'));\n\nvar server = app.listen(3000);\n```\n\nNow we run the server, which will listen on port 3000 for requests for `/model.json`.\n\n```sh\nnode index.js\n```\n\n### Retrieving Data from the Virtual JSON resource\n\nNow that we’ve built a simple virtual JSON document with a single read-only key “greeting”, we will create a test web page and retrieve this key from the server.\n\nNow create an index.html file with the following contents:\n\n```html\n\n\n \n \n \n \n \n \n \n\n```\n\nNow visit http://localhost:3000/index.html and you should see the message retrieved from the server:\n\n\n\n*This section was taken from [Falcor documentation site](http://netflix.github.io/falcor/).*\n", "html": "Falcor is a JavaScript library for efficient data fetching.
\nFalcor lets you represent all your remote data sources as a single domain model via a virtual JSON graph. You code the same way no matter where the data is, whether in memory on the client or over the network on the server.
\nA JavaScript-like path syntax makes it easy to access as much or as little data as you want, when you want it. You retrieve your data using familiar JavaScript operations like get, set, and call. If you know your data, you know your API.
\nFalcor automatically traverses references in your graph and makes requests as needed. Falcor transparently handles all network communications, opportunistically batching and de-duping requests.
\nYou can check out a working example server for a Netflix-like application here right now. Alternately you can go through this barebones tutorial in which we use the Falcor Router to create a Virtual JSON resource. In this tutorial we will use Falcor’s express middleware to serve the Virtual JSON resource on an application server at the URL /model.json. We will also host a static web page on the same server which retrieves data from the Virtual JSON resource.
\nIn this example we will use the Falcor Router to build a Virtual JSON resource on an app server and host it at /model.json. The JSON resource will contain the following contents:
{\n "greeting": "Hello World"\n}\nNormally Routers retrieve the data for their Virtual JSON resource from backend datastores or other web services on-demand. However in this simple tutorial the Router will simply return static data for a single key.
\nFirst we create a folder for our application server.
\nmkdir falcor-app-server\ncd falcor-app-server\nnpm init\nNow we install the falcor Router.
\nnpm install falcor-router --save\nThen install express and falcor-express. Support for restify, and Hapi is also available.
\nnpm install express --save\nnpm install falcor-express --save\nNow we create an index.js file with the following contents:
// index.js\nvar falcorExpress = require('falcor-express');\nvar Router = require('falcor-router');\nvar express = require('express');\nvar app = express();\n\napp.use('/model.json', falcorExpress.dataSourceRoute(function (req, res) {\n // create a Virtual JSON resource with single key (“greeting”)\n return new Router([\n {\n // match a request for the key “greeting”\n route: 'greeting',\n // respond with a PathValue with the value of “Hello World”\n get: function () {\n return {\n path: ['greeting'],\n value: 'Hello World'\n };\n }\n }\n ]);\n}));\n\n// serve static files from current directory\napp.use(express.static(__dirname + '/'));\n\nvar server = app.listen(3000);\nNow we run the server, which will listen on port 3000 for requests for /model.json.
node index.js\nNow that we’ve built a simple virtual JSON document with a single read-only key “greeting”, we will create a test web page and retrieve this key from the server.
\nNow create an index.html file with the following contents:
\n<!-- index.html -->\n<html>\n <head>\n <!-- Do _not_ rely on this URL in production. Use only during development. -->\n <script src="//netflix.github.io/falcor/build/falcor.browser.js"></script>\n <script>\n var model = new falcor.Model({\n source: new falcor.HttpDataSource('/model.json')\n });\n\n // retrieve the “greeting” key from the root of the Virtual JSON resource\n model\n .get('greeting')\n .then(function (response) {\n document.write(response.json.greeting);\n });\n </script>\n </head>\n <body>\n </body>\n</html>\nNow visit http://localhost:3000/index.html and you should see the message retrieved from the server:
\n
This section was taken from Falcor documentation site.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/FALCOR.md" }, { "name": "Flow", "description": "a static type checker, designed to find type errors in JavaScript programs", "markdown": "\n\n# Flow\n\n[Flow](http://flowtype.org/) is a static type checker for JavaScript. It can be used to catch common bugs in JavaScript programs - such as silent type conversions, null dereferences and so on - often without requiring any changes to your code. It also adds type syntax to JavaScript, so that developers can express invariants about their code and have them maintained automatically.\n\nFlow’s type checking is **opt-in**: files are not type checked unless you ask it to. This means that you can gradually convert your JavaScript codebase to Flow while reaping incremental benefits. When you do opt-in a file, Flow tries to type check the code automatically by performing type inference, reporting errors without further manual guidance. This simple workflow is usually sufficient when your codebase is broken down into small files, each defining a module that exports a well-defined interface. However, for some files (e.g., monolithic libraries), the analysis Flow performs might turn out to be too imprecise, causing lots of spurious errors to be reported. In such cases, the developer can either try to manually guide Flow with type annotations, or switch to a [weaker mode](http://flowtype.org/docs/existing.html#weak-mode) with limited type inference to reduce noise.\n\nFlow’s type checking is **online**: it performs an initial analysis of all files in a code base, and then monitors those files for subsequent changes, type checking them and other dependencies piecemeal and proactively in the background. For the developer, this means that there are no perceptible compile-time delays; saving a bunch of files in an editor or rebasing a set of files in a repository automatically triggers type checking, storing the results in a persistent server, so that they are available instantaneously when queried.\n\n## How does it work?\n\nFlow designed to find type errors in JavaScript programs:\n\n```js\n/* @flow */\nfunction foo(x) {\n return x * 10;\n}\n\nfoo('Hello, world!');\n```\n\n```sh\n$> flow\n\nhello.js:5:5,19: string\nThis type is incompatible with\n hello.js:3:10,15: number\n```\n\nFlow also lets you gradually evolve JavaScript code into typed code:\n\n```js\n/* @flow */\nfunction foo(x: string, y: number): string {\n return x.length * y;\n}\n\nfoo('Hello', 42);\n```\n\n```sh\n$> flow\n\nhello.js:3:10,21: number\nThis type is incompatible with\n hello.js:2:37,42: string\n```\n\nTyped Flow code easily transforms down to regular JavaScript, so it runs anywhere.\n\n## Why Flow?\n\nThe goal of Flow is to find errors in JavaScript code with little programmer effort. Flow relies heavily on **type inference** to find type errors even when the program has not been annotated - it precisely tracks the types of variables as they flow through the program.\n\nAt the same time, Flow is a **gradual** type system. Any parts of your program that are dynamic in nature can easily bypass the type checker, so you can mix statically typed code with dynamic code.\n\nFlow also supports a highly **expressive** type language. Flow types can express much more fine-grained distinctions than traditional type systems. For example, Flow helps you catch errors involving null, unlike most type systems.\n\n## Using Flow\n\nStart with [Getting Started](http://flowtype.org/docs/getting-started.html) guide to download and try Flow yourself. Flow is open-source, so you can also start with the code on the [GitHub repo](https://github.com/facebook/flow).\n\n----------\n\n*Source:*\n\n- [Flow | A static type checker for JavaScript](http://flowtype.org/)*.*\n", "html": "Flow is a static type checker for JavaScript. It can be used to catch common bugs in JavaScript programs - such as silent type conversions, null dereferences and so on - often without requiring any changes to your code. It also adds type syntax to JavaScript, so that developers can express invariants about their code and have them maintained automatically.
\nFlow’s type checking is opt-in: files are not type checked unless you ask it to. This means that you can gradually convert your JavaScript codebase to Flow while reaping incremental benefits. When you do opt-in a file, Flow tries to type check the code automatically by performing type inference, reporting errors without further manual guidance. This simple workflow is usually sufficient when your codebase is broken down into small files, each defining a module that exports a well-defined interface. However, for some files (e.g., monolithic libraries), the analysis Flow performs might turn out to be too imprecise, causing lots of spurious errors to be reported. In such cases, the developer can either try to manually guide Flow with type annotations, or switch to a weaker mode with limited type inference to reduce noise.
\nFlow’s type checking is online: it performs an initial analysis of all files in a code base, and then monitors those files for subsequent changes, type checking them and other dependencies piecemeal and proactively in the background. For the developer, this means that there are no perceptible compile-time delays; saving a bunch of files in an editor or rebasing a set of files in a repository automatically triggers type checking, storing the results in a persistent server, so that they are available instantaneously when queried.
\nFlow designed to find type errors in JavaScript programs:
\n/* @flow */\nfunction foo(x) {\n return x * 10;\n}\n\nfoo('Hello, world!');\n$> flow\n\nhello.js:5:5,19: string\nThis type is incompatible with\n hello.js:3:10,15: number\nFlow also lets you gradually evolve JavaScript code into typed code:
\n/* @flow */\nfunction foo(x: string, y: number): string {\n return x.length * y;\n}\n\nfoo('Hello', 42);\n$> flow\n\nhello.js:3:10,21: number\nThis type is incompatible with\n hello.js:2:37,42: string\nTyped Flow code easily transforms down to regular JavaScript, so it runs anywhere.
\nThe goal of Flow is to find errors in JavaScript code with little programmer effort. Flow relies heavily on type inference to find type errors even when the program has not been annotated - it precisely tracks the types of variables as they flow through the program.
\nAt the same time, Flow is a gradual type system. Any parts of your program that are dynamic in nature can easily bypass the type checker, so you can mix statically typed code with dynamic code.
\nFlow also supports a highly expressive type language. Flow types can express much more fine-grained distinctions than traditional type systems. For example, Flow helps you catch errors involving null, unlike most type systems.
\nStart with Getting Started guide to download and try Flow yourself. Flow is open-source, so you can also start with the code on the GitHub repo.
\nSource:
\n\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/FLOW.md" }, { "name": "Flux", "description": "an application structure focusing on improved data flow", "markdown": "\n\n# Flux\n\n[Flux](https://facebook.github.io/flux/) is an application structure that is developed and used at Facebook to complement [React](/_glossary/REACT.md)’s one-way data flow. With Flux, application state and logic are contained in stores.\n", "html": "Flux is an application structure that is developed and used at Facebook to complement React’s one-way data flow. With Flux, application state and logic are contained in stores.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/FLUX.md" }, { "name": "Four", "description": "a framework to develop 3D content for the web", "markdown": "\n\n# Four\n\n[Four](https://github.com/allotrop3/four) is a high level graphics API based on WebGL 1.0 for developing 3D content for the web. It lets you avoid the burden of repetition and complexity to speed up and simplify the development while exposing the flexibility of the [WebGL](/_glossary/WEBGL.md) API.\n\nHere are an [introduction](http://www.sitepoint.com/introducing-four-webgl-easier/) and a [demo](http://allotrop3.github.io/four/).\n", "html": "Four is a high level graphics API based on WebGL 1.0 for developing 3D content for the web. It lets you avoid the burden of repetition and complexity to speed up and simplify the development while exposing the flexibility of the WebGL API.
\nHere are an introduction and a demo.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/FOUR.md" }, { "name": "Grunt", "description": "a task runner aiming at automating tedious and possibly complex tasks", "markdown": "\n\n# Grunt\n\n[Grunt](http://gruntjs.com/) is a task runner aiming at automating tedious and possibly complex tasks. The idea behind Grunt (and its peer [Gulp](/_glossary/GULP.md)) is to define tasks that perform (usually file-based) actions. These tasks can then be run through the command line or as part of another build step.\n", "html": "Grunt is a task runner aiming at automating tedious and possibly complex tasks. The idea behind Grunt (and its peer Gulp) is to define tasks that perform (usually file-based) actions. These tasks can then be run through the command line or as part of another build step.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/GRUNT.md" }, { "name": "Gulp", "description": "a task runner aiming at automating tedious and possibly complex tasks", "markdown": "\n\n# Gulp\n\n[Gulp](http://gulpjs.com/) is a task runner aiming at automating tedious and possibly complex tasks. The idea behind Gulp (and its peer [Grunt](/_glossary/GRUNT.md)) is to define tasks that perform (usually file-based) actions. These tasks can then be run through the command line or as part of another build step. \n\nGulp also owes its success to its very large ecosystem of plugins, making it easy to perform everyday’s tasks without having to write much code.\n", "html": "Gulp is a task runner aiming at automating tedious and possibly complex tasks. The idea behind Gulp (and its peer Grunt) is to define tasks that perform (usually file-based) actions. These tasks can then be run through the command line or as part of another build step.
\nGulp also owes its success to its very large ecosystem of plugins, making it easy to perform everyday’s tasks without having to write much code.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/GULP.md" }, { "name": "Hapi", "description": "a Node JS framework for writing services and more", "markdown": "\n\n# Hapi\n\n[Hapi](http://hapijs.com/) is a simple to use configuration-centric framework with built-in support for input validation, caching, authentication, and other essential facilities for building web and services applications. Hapi enables developers to focus on writing reusable application logic in a highly modular and prescriptive approach.\n", "html": "Hapi is a simple to use configuration-centric framework with built-in support for input validation, caching, authentication, and other essential facilities for building web and services applications. Hapi enables developers to focus on writing reusable application logic in a highly modular and prescriptive approach.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/HAPI.md" }, { "name": "Hoisting", "description": "an action performed by the JavaScript interpreter that moves function and variable declarations to the top of their containing scope", "markdown": "\n\n# Hoisting\n\n[“Hoisting”](http://www.adequatelygood.com/JavaScript-Scoping-and-Hoisting.html) is an action performed by the JavaScript interpreter that moves function declarations of the form `function foo() {}`, and variable declarations of the form `var foo;` to the top of their containing scope. During this process, only the actual declarations are moved; any value assignments are left in the place where they were written.\n", "html": "“Hoisting” is an action performed by the JavaScript interpreter that moves function declarations of the form function foo() {}, and variable declarations of the form var foo; to the top of their containing scope. During this process, only the actual declarations are moved; any value assignments are left in the place where they were written.
IIFE (for Immediately Invoked Function Expression) is a function that gets called immediately after declaration. It is most often used to create a scoping context (a context in which all variables and function definitions are scoped).
\nAn IIFE can be written with the calling brackets (()) inside of the wrapping brackets:
(function foo () {\n // [body]\n}());\nOr with the calling brackets on the outside:
\n(function foo () {\n // [body]\n})();\nThe examples above are both named IIFE’s (foo) but it is also quite common to write them anonymously (without a function name).
Ionic is a HTML5 mobile framework to build beautiful hybrid native mobile applications using AngularJS and Cordova. It comes accompanied with a powerful CLI to create, build, test and deploy your applications into any platform. The framework also offers live reloading features to apply live changes to the application.
\nWith the advent of Angular 2, the Ionic team have started working on Ionic 2, which is a complete rewrite of Ionic.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/IONIC.md" }, { "name": "Isomorphic", "description": "an application is said to be isomorphic (universal) when its code can run both in the client and the server", "markdown": "\n\n# Isomorphic\n\nAn isomorphic (or [preferably](https://medium.com/@mjackson/universal-javascript-4761051b7ae9) [universal](/_glossary/UNIVERSAL.md)) application is one whose code (in this case, JavaScript) can run both in the server and the client.\n\nThe underlying idea is to allow the server to render and handle routing of an application for non-JavaScript users, while also making it fully working in the browser for fast interactions without involving traditional page reloads.\n\nIn an isomorphic application, the initial request made by the web browser is processed by the server while subsequent requests are processed by the client.\n", "html": "An isomorphic (or preferably universal) application is one whose code (in this case, JavaScript) can run both in the server and the client.
\nThe underlying idea is to allow the server to render and handle routing of an application for non-JavaScript users, while also making it fully working in the browser for fast interactions without involving traditional page reloads.
\nIn an isomorphic application, the initial request made by the web browser is processed by the server while subsequent requests are processed by the client.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/ISOMORPHIC.md" }, { "name": "Jasmine", "description": "a testing framework for BDD (Behaviour-Driven Development)", "markdown": "\n\n# Jasmine\n\n[Jasmine](http://jasmine.github.io/) is a BDD framework for testing JavaScript code. It does not depend on any other JavaScript frameworks. It does not require a DOM. \n\nJasmine is developed by [Pivotal Labs](http://pivotal.io/labs), and has many features like [Spies](http://jasmine.github.io/2.0/introduction.html#section-Spies) built in. \n\nIt also has support for mocking [AJAX](http://jasmine.github.io/2.0/ajax.html).\n", "html": "Jasmine is a BDD framework for testing JavaScript code. It does not depend on any other JavaScript frameworks. It does not require a DOM.
\nJasmine is developed by Pivotal Labs, and has many features like Spies built in.
\nIt also has support for mocking AJAX.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/JASMINE.md" }, { "name": "Jest ", "description": "A unit testing framework", "markdown": "\n\n# Jest\n\n[Jest](https://facebook.github.io/jest/) is a unit testing framework.\n\n* **Easy setup**: Complete and easy to set-up JavaScript testing solution. Works out of the box for any React project.\n* **Instant feedback**: Fast interactive watch mode runs only test files related to changed files and is optimized to give signal quickly.\n* **Snapshot testing**: Capture snapshots of React trees or other serializable values to simplify testing and to analyze how state changes over time.\n\n## Philosophies\n\nOne of Jest’s philosophies is to provide an integrated “zero-configuration” experience. We observed that when engineers are provided with ready-to-use tools, they end up writing more tests, which in turn results in more stable and healthy codebases.\n", "html": "Jest is a unit testing framework.
\nOne of Jest’s philosophies is to provide an integrated “zero-configuration” experience. We observed that when engineers are provided with ready-to-use tools, they end up writing more tests, which in turn results in more stable and healthy codebases.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/JEST.md" }, { "name": "jQuery", "description": "a fast, small, and feature-rich client-side library", "markdown": "\n\n# jQuery\n\n[jQuery](https://jquery.com/) is a fast, small, and feature-rich JavaScript library. It makes things like HTML document traversal and manipulation, event handling, animation, and [AJAX](/_glossary/AJAX.md) much simpler with an easy-to-use API that works across a multitude of browsers. With a combination of versatility and extensibility, jQuery has changed the way that millions of people write JavaScript.\n", "html": "jQuery is a fast, small, and feature-rich JavaScript library. It makes things like HTML document traversal and manipulation, event handling, animation, and AJAX much simpler with an easy-to-use API that works across a multitude of browsers. With a combination of versatility and extensibility, jQuery has changed the way that millions of people write JavaScript.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/JQUERY.md" }, { "name": "JSCS", "description": "a JavaScript code linter", "markdown": "\n\n# JSCS\n\n[JSCS — JavaScript Code Style](http://jscs.info/) is different from the others in that it doesn’t do anything unless you give it a configuration file or tell it to use a preset. You can download configurations from their website, so it’s not a big problem, and it has a number of presets, such as the [jQuery](/_glossary/JQUERY.md) coding style preset and the Google preset. JSCS is a code style checker. This means it only catches issues related to code formatting, and not potential bugs or errors.\n", "html": "JSCS — JavaScript Code Style is different from the others in that it doesn’t do anything unless you give it a configuration file or tell it to use a preset. You can download configurations from their website, so it’s not a big problem, and it has a number of presets, such as the jQuery coding style preset and the Google preset. JSCS is a code style checker. This means it only catches issues related to code formatting, and not potential bugs or errors.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/JSCS.md" }, { "name": "JSHint", "description": "a JavaScript code linter", "markdown": "\n\n# JSHint\n\n[JSHint](http://jshint.com/) was created as a more configurable version of [JSLint](/_glossary/JSLINT.md) (of which it is a fork). You can configure every rule, and put them into a configuration file, which makes JSHint easy to use in bigger projects. JSHint also has good documentation for each of the rules, so you know exactly what they do.\n", "html": "JSHint was created as a more configurable version of JSLint (of which it is a fork). You can configure every rule, and put them into a configuration file, which makes JSHint easy to use in bigger projects. JSHint also has good documentation for each of the rules, so you know exactly what they do.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/JSHINT.md" }, { "name": "JSLint", "description": "a JavaScript code linter", "markdown": "\n\n# JSLint\n\n[JSLint](http://www.jslint.com/) is a static analysis “code quality” tool for JavaScript.The downsides are that JSLint is not configurable or extensible. You can’t disable many features at all, and some of them lack documentation.\n", "html": "JSLint is a static analysis “code quality” tool for JavaScript.The downsides are that JSLint is not configurable or extensible. You can’t disable many features at all, and some of them lack documentation.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/JSLINT.md" }, { "name": "JSON-LD", "description": "JSON for Linked Data", "markdown": "\n\n# JSON-LD \n\n[JSON-LD (JSON for Linked Data)](http://json-ld.org/) is a lightweight Linked Data format. It is easy for humans to read and write. It is based on the already successful JSON format and provides a way to help [JSON](/_glossary/JSON.md) data interoperate at Web-scale. JSON-LD is an ideal data format for programming environments, REST Web services, and unstructured databases such as [CouchDB](/_glossary/COUCHDB.md) and [MongoDB](/_glossary/MONGODB.md). \n", "html": "JSON-LD (JSON for Linked Data) is a lightweight Linked Data format. It is easy for humans to read and write. It is based on the already successful JSON format and provides a way to help JSON data interoperate at Web-scale. JSON-LD is an ideal data format for programming environments, REST Web services, and unstructured databases such as CouchDB and MongoDB.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/JSON-LD.md" }, { "name": "JSON", "description": "a lightweight data-interchange format", "markdown": "\n\n# JSON\n\n[JSON (JavaScript Object Notation)](http://www.json.org/) is a lightweight data-interchange format. It is widely used in [RESTful](https://en.wikipedia.org/wiki/Representational_state_transfer) web services. It is both easy for humans to read and write and for machines to parse and generate.\n", "html": "JSON (JavaScript Object Notation) is a lightweight data-interchange format. It is widely used in RESTful web services. It is both easy for humans to read and write and for machines to parse and generate.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/JSON.md" }, { "name": "JSPM", "description": "like npm with its own build system and multiple resources management", "markdown": "\n\n# JSPM\n\n[JSPM](http://jspm.io/) is a package manager coupled with its own build system. Thus, any kind of module can be loaded (e.g ES6, AMD, CommonJS) within the current installed modules. Those modules can be loaded from [npm](/_glossary/npm.md), as well as Github, Bitbucket or Bower. JSPM creates its own dependencies folder in the project directory, called `jspm_packages`, instead of the regular `node_modules` folder.\n\n## Usage\n\n- `npm install -g jspm`: Install the JSPM CLI.\n- `jspm init`: Initialize the current project with JSPM.\n- `jspm install lodash`: Install packages, just like NPM.\n- `jspm install github:lodash/lodash@4.6.1`: Install the specified. version from Github.\n- `jspm bundle app/main --inject`: Bundle the app, just like [Browserify](http://browserify.org/).\n\nSee the [JSPM documentation](http://jspm.io/docs/) for further details.\n", "html": "JSPM is a package manager coupled with its own build system. Thus, any kind of module can be loaded (e.g ES6, AMD, CommonJS) within the current installed modules. Those modules can be loaded from npm, as well as Github, Bitbucket or Bower. JSPM creates its own dependencies folder in the project directory, called jspm_packages, instead of the regular node_modules folder.
npm install -g jspm: Install the JSPM CLI.jspm init: Initialize the current project with JSPM.jspm install lodash: Install packages, just like NPM.jspm install github:lodash/lodash@4.6.1: Install the specified. version from Github.jspm bundle app/main --inject: Bundle the app, just like Browserify.See the JSPM documentation for further details.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/JSPM.md" }, { "name": "JSX", "description": "an XML-like syntax extension to JavaScript", "markdown": "\n\n# JSX\n\n[JSX](https://facebook.github.io/jsx/) is an XML-like syntax extension to JavaScript. It allows developers to write HTML directly in JS but needs to be transpiled before it can be used in the browser. JSX is developed at Facebook and mostly used to complement [React](/_glossary/REACT.md).\n", "html": "JSX is an XML-like syntax extension to JavaScript. It allows developers to write HTML directly in JS but needs to be transpiled before it can be used in the browser. JSX is developed at Facebook and mostly used to complement React.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/JSX.md" }, { "name": "Knockout", "description": "a library that helps developers creating user interfaces with a clean underlying data model", "markdown": "\n\n# Knockout\n\n[Knockout](http://knockoutjs.com/) (shortened as *KO*) is a JavaScript library that helps developers creating rich, responsive display and editor user interfaces with a clean underlying data model. Knockout helps implementing sections of UI that update dynamically (e.g. changes depending on user’s actions or when external data source gets updated) more simply and maintainably.\n", "html": "Knockout (shortened as KO) is a JavaScript library that helps developers creating rich, responsive display and editor user interfaces with a clean underlying data model. Knockout helps implementing sections of UI that update dynamically (e.g. changes depending on user’s actions or when external data source gets updated) more simply and maintainably.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/KNOCKOUT.md" }, { "name": "LocalForage", "description": "a fast and simple storage library for JavaScript", "markdown": "\n\n# localForage\n\n**Offline storage, improved.**\n\n[localForage](https://mozilla.github.io/localForage/#localforage) is a JavaScript library that improves the offline experience of your web app by using an asynchronous data store with a simple, `localStorage`-like API. It allows developers to store many types of data instead of just strings.\n\nlocalForage includes a localStorage-backed fallback store for browsers with no IndexedDB or WebSQL support. Asynchronous storage is available in the current versions of all major browsers: Chrome, Firefox, Internet Explorer, and Safari (including Safari Mobile).\n\n**localForage offers a callback API as well as support for the** [ES6 Promises API](/_glossary/PROMISE.md), so you can use whichever you prefer.\n\n## Installation\n\nTo use localForage, [download the latest release](https://github.com/mozilla/localForage/releases) or install with npm:\n\n```sh\nnpm install localforage\n```\n\nor bower:\n\n```sh\nbower install localforage\n```\n\nThen simply include the JS file and start using localForage:\n\n```html\n.\n```\n\nYou don’t need to run any init method or wait for any `onready` events.\n\n## How to use localForage\n\n### Callbacks\n\nBecause localForage uses async storage, it has an async API. It’s otherwise exactly the same as the [localStorage API](https://hacks.mozilla.org/2009/06/localstorage/).\n\n```js\n// In localStorage, we would do:\nvar obj = { value: 'hello world' };\nlocalStorage.setItem('key', JSON.stringify(obj));\nalert(obj.value);\n\n// With localForage, we use callbacks:\nlocalforage.setItem('key', obj, function(err, result) {\n alert(result.value);\n});\n```\n\nSimilarly, please don’t expect a return value from calls to `localforage.getItem()`. Instead, use a callback:\n\n```js\n// Synchronous; slower!\nvar value = JSON.parse(localStorage.getItem('key'));\nalert(value);\n\n// Async, fast, and non-blocking!\nlocalforage.getItem('key', function(err, value) { alert(value) });\n```\n\nCallbacks in localForage are Node-style (error argument first) since version `0.9.3`. This means if you’re using callbacks, your code should look like this:\n\n```js\n// Use err as your first argument.\nlocalforage.getItem('key', function(err, value) {\n if (err) {\n console.error('Oh noes!');\n } else {\n alert(value);\n }\n});\n```\n\nYou can store any type in localForage; you aren’t limited to strings like in localStorage. Even if localStorage is your storage backend, localForage automatically does `JSON.parse()` and `JSON.stringify()` when getting/setting values.\n\n### Promises\n\nPromises are pretty cool! If you’d rather use promises than callbacks, localForage supports that too:\n\n```js\nfunction doSomethingElse(value) {\n console.log(value);\n}\n\n// With localForage, we allow promises:\nlocalforage.setItem('key', 'value').then(doSomethingElse);\n```\n\nWhen using Promises, `err` is **not** the first argument passed to a function. Instead, you handle an error with the rejection part of the Promise:\n\n```js\n// A full setItem() call with Promises.\nlocalforage.setItem('key', 'value').then(function(value) {\n alert(value + ' was set!');\n}, function(error) {\n console.error(error);\n});\n```\n\nlocalForage relies on native [ES6 Promises](/_glossary/PROMISE.md), but [ships with an awesome polyfill](https://github.com/jakearchibald/es6-promise) for browsers that don’t support ES6 Promises yet.\n\n### Storing Blobs, TypedArrays, and other JS objects\n\nlocalForage supports storing all native JS objects that can be serialized to JSON, as well as ArrayBuffers, Blobs, and TypedArrays. Check the [API docs](https://mozilla.github.io/localForage/#setitem) for a full list of types supported by localForage.\n\nAll types are supported in every storage backend, though storage limits in localStorage make storing many large Blobs impossible.\n\n### Configuration\n\nYou can set database information with the `config()` method. Available options are `driver`, `name`, `storeName`, `version`, `size`, and `description`.\n\nExample:\n\n```js\nlocalforage.config({\n driver : localforage.WEBSQL, // Force WebSQL; same as using setDriver()\n name : 'myApp',\n version : 1.0,\n size : 4980736, // Size of database, in bytes. WebSQL-only for now.\n storeName : 'keyvaluepairs', // Should be alphanumeric, with underscores.\n description : 'some description'\n});\n```\n\n**Note**: you must call `config()` before you interact with your data. This means calling `config()` before using `getItem()`, `setItem()`, `removeItem()`, `clear()`, `key()`, `keys()` or `length()`.\n\n### Multiple instances\n\nYou can create multiple instances of localForage that point to different stores using `createInstance`. All the configuration options used by [`config`](https://github.com/mozilla/localForage#configuration) are supported.\n\n```js\nvar store = localforage.createInstance({\n name: 'nameHere'\n});\n\nvar otherStore = localforage.createInstance({\n name: 'otherName'\n});\n\n// Setting the key on one of these doesn’t affect the other.\nstore.setItem('key', 'value');\notherStore.setItem('key', 'value2');\n```\n\n### RequireJS\n\nYou can use localForage with [RequireJS](/_glossary/REQUIREJS.md):\n\n```js\ndefine(['localforage'], function(localforage) {\n // As a callback:\n localforage.setItem('mykey', 'myvalue', console.log);\n\n // With a Promise:\n localforage.setItem('mykey', 'myvalue').then(console.log);\n});\n```\n\n### Browserify and Webpack\n\nlocalForage 1.3+ works with both Browserify and Webpack. If you’re using an earlier version of localForage and are having issues with Browserify or Webpack, please upgrade to 1.3.0 or above.\n\nIf you’re using localForage in your own build system (e.g. browserify or webpack) make sure you have the [required plugins and transformers](https://github.com/mozilla/localForage/blob/master/package.json#L24) installed (e.g. `$ npm install --save-dev babel-plugin-system-import-transformer`).\n\n### Framework Support\n\nIf you use a framework listed, ther’s a localForage storage driver for the models in your framework so you can store data offline with localForage. We have drivers for the following frameworks:\n\n- [AngularJS](https://github.com/ocombe/angular-localForage)\n- [Backbone](https://github.com/mozilla/localForage-backbone)\n- [Ember](https://github.com/genkgo/ember-localforage-adapter)\n\n### Custom Drivers\n\nYou can create your own driver if you want; see the [`defineDriver`](https://mozilla.github.io/localForage/#definedriver) API docs.\n\nThere is a [list of custom drivers on the wiki](https://github.com/mozilla/localForage/wiki/Custom-Drivers).\n\n----------\n\n*Source:*\n\n- [mozilla/localForage](https://github.com/mozilla/localForage)*. Official GitHub repo.*\n- [localForage API Reference](https://mozilla.github.io/localForage/)*.*\n", "html": "Offline storage, improved.
\nlocalForage is a JavaScript library that improves the offline experience of your web app by using an asynchronous data store with a simple, localStorage-like API. It allows developers to store many types of data instead of just strings.
localForage includes a localStorage-backed fallback store for browsers with no IndexedDB or WebSQL support. Asynchronous storage is available in the current versions of all major browsers: Chrome, Firefox, Internet Explorer, and Safari (including Safari Mobile).
\nlocalForage offers a callback API as well as support for the ES6 Promises API, so you can use whichever you prefer.
\nTo use localForage, download the latest release or install with npm:
\nnpm install localforage\nor bower:
\nbower install localforage\nThen simply include the JS file and start using localForage:
\n<script src="localforage.js"></script>.\nYou don’t need to run any init method or wait for any onready events.
Because localForage uses async storage, it has an async API. It’s otherwise exactly the same as the localStorage API.
\n// In localStorage, we would do:\nvar obj = { value: 'hello world' };\nlocalStorage.setItem('key', JSON.stringify(obj));\nalert(obj.value);\n\n// With localForage, we use callbacks:\nlocalforage.setItem('key', obj, function(err, result) {\n alert(result.value);\n});\nSimilarly, please don’t expect a return value from calls to localforage.getItem(). Instead, use a callback:
// Synchronous; slower!\nvar value = JSON.parse(localStorage.getItem('key'));\nalert(value);\n\n// Async, fast, and non-blocking!\nlocalforage.getItem('key', function(err, value) { alert(value) });\nCallbacks in localForage are Node-style (error argument first) since version 0.9.3. This means if you’re using callbacks, your code should look like this:
// Use err as your first argument.\nlocalforage.getItem('key', function(err, value) {\n if (err) {\n console.error('Oh noes!');\n } else {\n alert(value);\n }\n});\nYou can store any type in localForage; you aren’t limited to strings like in localStorage. Even if localStorage is your storage backend, localForage automatically does JSON.parse() and JSON.stringify() when getting/setting values.
Promises are pretty cool! If you’d rather use promises than callbacks, localForage supports that too:
\nfunction doSomethingElse(value) {\n console.log(value);\n}\n\n// With localForage, we allow promises:\nlocalforage.setItem('key', 'value').then(doSomethingElse);\nWhen using Promises, err is not the first argument passed to a function. Instead, you handle an error with the rejection part of the Promise:
// A full setItem() call with Promises.\nlocalforage.setItem('key', 'value').then(function(value) {\n alert(value + ' was set!');\n}, function(error) {\n console.error(error);\n});\nlocalForage relies on native ES6 Promises, but ships with an awesome polyfill for browsers that don’t support ES6 Promises yet.
\nlocalForage supports storing all native JS objects that can be serialized to JSON, as well as ArrayBuffers, Blobs, and TypedArrays. Check the API docs for a full list of types supported by localForage.
\nAll types are supported in every storage backend, though storage limits in localStorage make storing many large Blobs impossible.
\nYou can set database information with the config() method. Available options are driver, name, storeName, version, size, and description.
Example:
\nlocalforage.config({\n driver : localforage.WEBSQL, // Force WebSQL; same as using setDriver()\n name : 'myApp',\n version : 1.0,\n size : 4980736, // Size of database, in bytes. WebSQL-only for now.\n storeName : 'keyvaluepairs', // Should be alphanumeric, with underscores.\n description : 'some description'\n});\nNote: you must call config() before you interact with your data. This means calling config() before using getItem(), setItem(), removeItem(), clear(), key(), keys() or length().
You can create multiple instances of localForage that point to different stores using createInstance. All the configuration options used by config are supported.
var store = localforage.createInstance({\n name: 'nameHere'\n});\n\nvar otherStore = localforage.createInstance({\n name: 'otherName'\n});\n\n// Setting the key on one of these doesn’t affect the other.\nstore.setItem('key', 'value');\notherStore.setItem('key', 'value2');\nYou can use localForage with RequireJS:
\ndefine(['localforage'], function(localforage) {\n // As a callback:\n localforage.setItem('mykey', 'myvalue', console.log);\n\n // With a Promise:\n localforage.setItem('mykey', 'myvalue').then(console.log);\n});\nlocalForage 1.3+ works with both Browserify and Webpack. If you’re using an earlier version of localForage and are having issues with Browserify or Webpack, please upgrade to 1.3.0 or above.
\nIf you’re using localForage in your own build system (e.g. browserify or webpack) make sure you have the required plugins and transformers installed (e.g. $ npm install --save-dev babel-plugin-system-import-transformer).
If you use a framework listed, ther’s a localForage storage driver for the models in your framework so you can store data offline with localForage. We have drivers for the following frameworks:
\n\nYou can create your own driver if you want; see the defineDriver API docs.
There is a list of custom drivers on the wiki.
\nSource:
\nLodash is a small modularized library which provides a bunch of helpers to work with Javascript data types (string, object, etc.) in a much more simpler way. Every single helper can be required and used itself without requiring the whole library. Additionally, it makes Javascript code look elegant and more efficient by offering functional style, method chaining and more.
\nThink of Lodash as an utility library to simplify Javascript development by providing functions for Javascript basic types, such as:
\nmap, reduce, filter, merge, difference…capitalize, camelCase, truncate, template…find, where, contains, any, all…pick, omit, forIn, pluck…property, method, get, set…partial, curry, compose, debounce…It also provides an API for chaining function calls in a “pipe-like” flavor:
\n_.chain(myArray)\n .map(x => x * 3)\n .filter(x => x % 2)\n .sum()\n .value()\n // returns the sum of myArray after multiplying all elements by 3 and rejecting the odd numbers\nIt may be seen as alternative of Underscore.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/LODASH.md" }, { "name": "MEAN", "description": "the technology stack MongoDB, ExpressJS, AngularJS, and Node.js (MEAN)", "markdown": "\n\n# MEAN\n\n[MEAN](https://en.wikipedia.org/wiki/MEAN_(software_bundle)) is a software technology stack based on JavaScript for building web sites and web applications, and comprised of the following components: [MongoDB](/_glossary/MONGODB.md), [ExpressJS](/_glossary/EXPRESS.md), [Node.js](/_glossary/NODEJS.md), and [AngularJS](/_glossary/ANGULARJS.md).\n\n## Notable MEAN frameworks\n\n* [MEAN.JS](http://meanjs.org) MEAN.JS - Full-Stack JavaScript Using MongoDB, Express, AngularJS, and Node.js From Creators of MEAN.IO.\n* [MEAN.io](http://mean.io/) MEAN is an opinionated full-stack javascript framework - which simplifies and accelerates web application development.\n", "html": "MEAN) is a software technology stack based on JavaScript for building web sites and web applications, and comprised of the following components: MongoDB, ExpressJS, Node.js, and AngularJS.
\nIn software engineering, the mediator pattern defines an object that encapsulates how a set of objects interact. This pattern is considered to be a behavioral pattern due to the way it can alter the program’s running behavior.
\nUsually a program is made up of a large number of classes. So the logic and computation is distributed among these classes. However, as more classes are developed in a program, especially during maintenance and/or refactoring, the problem of communication between these classes may become more complex. This makes the program harder to read and maintain. Furthermore, it can become difficult to change the program, since any change may affect code in several other classes.
\nWith the mediator pattern, communication between objects is encapsulated with a mediator object. Objects no longer communicate directly with each other, but instead communicate through the mediator. This reduces the dependencies between communicating objects, thereby lowering the coupling.
\nThe essence of the Mediator Pattern is to “define an object that encapsulates how a set of objects interact.” It promotes loose coupling by keeping objects from referring to each other explicitly, and it allows their interaction to be varied independently. Client classes can use the mediator to send messages to other clients, and can receive messages from other clients via an event on the mediator class.
\n
The objects participating in this pattern are:
\nChatroomColleague objectsColleague objectsParticipantsMediatorMediatorIn the example code we have four participants that are joining in a chat session by registering with a Chatroom (the Mediator). Each participant is represented by a Participant object. Participants send messages to each other and the Chatroom handles the routing.
\nThis example is simple, but other complex rules could have been added, such as a “junk filter” to protect participants from receiving junk messages.
\nThe log function is a helper which collects and displays results.
\nclass Participant {\n constructor(name) {\n this.name = name;\n this.chatroom = null;\n }\n\n send(message, to) {\n this.chatroom.send(message, this, to);\n }\n\n receive(message, from) {\n log.add(from.name + " to " + this.name + ": " + message);\n }\n}\n\nlet Chatroom = function() {\n let participants = {};\n\n return { \n register: function(participant) {\n participants[participant.name] = participant;\n participant.chatroom = this;\n },\n\n send: function(message, from, to) {\n if (to) { // single message\n to.receive(message, from); \n } else { // broadcast message\n for (let key in participants) { \n if (participants[key] !== from) {\n participants[key].receive(message, from);\n }\n }\n }\n }\n };\n};\n\n// log helper\nlog = (function() {\n let log = '';\n\n return {\n add: msg => { log += msg + '\\n'; },\n show: () => { alert(log); log = ''; }\n }\n})();\n\nfunction run() {\n let yoko = new Participant('Yoko'),\n john = new Participant('John'),\n paul = new Participant('Paul'),\n ringo = new Participant('Ringo'),\n chatroom = new Chatroom(),\n\n chatroom.register(yoko);\n chatroom.register(john);\n chatroom.register(paul);\n chatroom.register(ringo);\n\n yoko.send('All you need is love.');\n yoko.send('I love you John.');\n john.send('Hey, no need to broadcast', yoko);\n paul.send('Ha, I heard that!');\n ringo.send('Paul, what do you think?', paul);\n\n log.show();\n}\n\nrun();\nSource:
\nAn optimization used to speed up consecutive function calls by caching the result of calls with identical input.
\nHere is an example of a memoizer function, taken from the book JavaScript The Good Parts by Douglas Crockford,\nthat caches the results from a fibonacci number generator function:
\nvar memoizer = function (memo, formula) {\n var recur = function (n) {\n var result = memo[n];\n if (typeof result !== 'number') {\n result = formula(recur, n);\n memo[n] = result;\n }\n return result;\n };\n return recur;\n};\n\nvar fibonacci = memoizer([0, 1], function (recur, n) {\n return recur(n − 1) + recur(n − 2);\n});\nMetalsmith is an abstraction for manipulating a directory of files. To put it simply, it is a static site generator.
\nMetalsmith, at its core, takes files in a source directory, perform operations on them via plugins, and writes those files into a destination directory. Plugins can do virtually anything: create new files, filter out files, modify files based on some logic, etc (note this means that plugin order does matter; transformations done by one plugin can be seen and used by following plugins, making the process a modular build pipeline). The entire ecosystem of plugins is what makes Metalsmith so flexible.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/METALSMITH.md" }, { "name": "Meteor", "description": "a JavaScript web framework that allows rapid prototypic web development", "markdown": "\n\n# Meteor\n\n[Meteor](https://www.meteor.com/) Meteor is JavaScript framework written using [Node.js](/_glossary/NODEJS.md). It integrates with [MongoDB](/_glossary/MONGODB.md) and uses the Distributed Data Protocol and a publish–subscribe pattern to enable automatic synching of data changes to clients without requiring the developer to write any synchronization code. \n", "html": "Meteor Meteor is JavaScript framework written using Node.js. It integrates with MongoDB and uses the Distributed Data Protocol and a publish–subscribe pattern to enable automatic synching of data changes to clients without requiring the developer to write any synchronization code.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/METEOR.md" }, { "name": "Mocha", "description": "an extensible testing framework for TDD (Test-Driven Development) or BDD (Behaviour-Driven Development)", "markdown": "\n\n# Mocha\n\n[Mocha](https://mochajs.org/) is an extensible, open-source JavaScript testing framework that runs in [Node.js](/_glossary/NODEJS.md) or the browser. It supports both TDD and BDD by allowing you to use any assertion library, such as [expect.js](https://github.com/Automattic/expect.js), [should.js](https://github.com/shouldjs/should.js), and [Chai](/_glossary/CHAI.md).\n\nMocha supports spies, stubs and mocks through libraries, such as [Sinon](https://github.com/sinonjs/sinon).\n\nMocha supports testing both synchronous and asynchronous code, including [promises](http://www.sitepoint.com/promises-in-javascript-unit-tests-the-definitive-guide/).\n", "html": "Mocha is an extensible, open-source JavaScript testing framework that runs in Node.js or the browser. It supports both TDD and BDD by allowing you to use any assertion library, such as expect.js, should.js, and Chai.
\nMocha supports spies, stubs and mocks through libraries, such as Sinon.
\nMocha supports testing both synchronous and asynchronous code, including promises.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/MOCHA.md" }, { "name": "Modernizr", "description": "a browser feature detection library, useful to modify page styles when a feature is not available in the browser", "markdown": "\n\n# Modernizr\n\n[Modernizr](https://modernizr.com/) is a feature detection library to determine which HTML/CSS features are available in the user’s browser.\n\nIt is done by injecting specific classes on the document’s root element, so that the designer or the developer can treat the page differently should a feature not be available in the browser.\n\nFor instance, if the browser does not support *CSS gradients*, Modernizr will add the class `no-cssgradients` to the document’s root element. That way, it is possible to create a rule that will set a regular background for non-supported browsers, like so:\n\n```css\n.no-cssgradients .my-element {\n background-color: red;\n}\n```\n\nAnother example is if the user has disabled JavaScript on the page, then Modernizr will inject a `no-js` style on the page. The design of the page can then be adapted based on the lack of JavaScript given how certain features are likely to be unavailable.\n", "html": "Modernizr is a feature detection library to determine which HTML/CSS features are available in the user’s browser.
\nIt is done by injecting specific classes on the document’s root element, so that the designer or the developer can treat the page differently should a feature not be available in the browser.
\nFor instance, if the browser does not support CSS gradients, Modernizr will add the class no-cssgradients to the document’s root element. That way, it is possible to create a rule that will set a regular background for non-supported browsers, like so:
.no-cssgradients .my-element {\n background-color: red;\n}\nAnother example is if the user has disabled JavaScript on the page, then Modernizr will inject a no-js style on the page. The design of the page can then be adapted based on the lack of JavaScript given how certain features are likely to be unavailable.
In software engineering, the module pattern is a design pattern used to implement the concept of software modules, defined by modular programming, in a programming language with incomplete direct support for the concept.
\nThis pattern can be implemented in several ways depending on the host programming language, such as the singleton design pattern, object-oriented static members in a class and procedural global functions.
\nThe module software design pattern provides the features and syntactic structure defined by the modular programming paradigm to programming languages that have incomplete support for the concept.
\n
In software development, source code can be organized into components that accomplish a particular function or contain everything necessary to accomplish a particular task. Modular programming is one of those approaches.
\nThe concept of a “module” is not fully supported in many common programming languages.
\nIn order to consider that a Singleton or any group of related code implements this pattern, the following features must be supplied:
\nJavaScript does not have built-in support for modules, but the community has created impressive work-arounds. The two most popular standards are:
\nIn the middle of 2015, TC39 have accepted the new standard ECMAScript 2015 (ES6) which supports built-in modules through the new syntax.
\n// helper/MathHelper.js\nmodule.exports = {\n add: function(left, right) {\n return left + right;\n },\n\n times: function(left, right) {\n return left * right;\n }\n}\n// program.js\nvar mathHelper = require('./helper/MathHelper');\n\nconsole.log(mathHelper.add(5, 8)); // 13\nconsole.log(mathHelper.times(3, 4)); // 12\n// helper/MathHelper.js\ndefine(function() {\n return {\n add: function(left, right) {\n return left + right;\n },\n\n times: function(left, right) {\n return left * right;\n }\n }\n});\n// program.js\nrequirejs(['helper/MathHelper'], function(matHelper) {\n console.log(mathHelper.add(5, 8)); // 13\n console.log(mathHelper.times(3, 4)); // 12\n});\n// helper/MathHelper.js\nexport function add(left, right) {\n return left + right;\n}\n\nexport function times(left, right) {\n return left * right;\n}\n// program.js\nimport { add, times } from './helper/MathHelper';\n\nconsole.log(add(5, 8)); // 13\nconsole.log(times(3, 4)); // 12\nThe Module pattern can be considered a creational pattern and a structural pattern. It manages the creation and organization of other elements, and groups them as the structural pattern does.
\nAn object that applies this pattern can provide the equivalent of a namespace, providing the initialization and finalization process of a static class or a class with static members with cleaner, more concise syntax and semantics.
\nIt supports specific cases where a class or object can be considered structured, procedural data. And, vice versa, migrate structured, procedural data, and considered as object-oriented.
\nSource:
\nMoment.js is a library that helps developing with dates. It supports manipulation of dates, parsing or validate dates, for example based on user inputs, and display dates in certain formats. The localization allows you to display or parse user friendly dates based on a locale and will also translated months etc.\nMoment.js can also handle durations, queries (like checking if a date is before another date) or custom extensions.
\nMoment Timezone is a extension of Moment.js which supports to work with different timezones on dates. It can show a specific time in different timezones.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/MOMENTJS.md" }, { "name": "MongoDB", "description": "a Javascript NoSQL database", "markdown": "\n\n# MongoDB\n\n[MongoDB](https://www.mongodb.org/) is a fast, reliable and performant Javascript-powered **NoSQL** database. It uses the concept of **Documents** which is a sort of [JSON](/_glossary/JSON.md)-like data model (called **BSON** for Binary Simple Object Model), making querying faster and easier.\n\nThe main advantage over traditional MySQL databases is the flexibility offered by the Document Model to achieve simpler and faster integration.\n", "html": "MongoDB is a fast, reliable and performant Javascript-powered NoSQL database. It uses the concept of Documents which is a sort of JSON-like data model (called BSON for Binary Simple Object Model), making querying faster and easier.
\nThe main advantage over traditional MySQL databases is the flexibility offered by the Document Model to achieve simpler and faster integration.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/MONGODB.md" }, { "name": "MooTools", "description": "a collection of JavaScript utilities designed for the intermediate to advanced JavaScript developer. It allows you to write powerful and flexible code with its elegant, well documented, and coherent APIs", "markdown": "\n\n# MooTools\n\n[MooTools](http://mootools.net/) (My Object-Oriented Tools) is a lightweight, object-oriented JavaScript framework. It is released under the free, open-source MIT License. It is used on more than 4% of all websites, and is one of the most popular JavaScript libraries.\n\n> **MooTools** is a collection of JavaScript utilities designed for the intermediate to advanced JavaScript developer. It allows you to write powerful and flexible code with its elegant, well documented, and coherent APIs.\n> \n> **MooTools** code is extensively documented and easy to read, enabling you to extend the functionality to match your requirements.\n>\n> — Official MooTools site.\n\n## History\n\nValerio Proietti first authored the framework and released it in September 2006 taking as his inspiration [Prototype](/_glossary/PROTOTYPE.md) and Dean Edward’s [base2](http://code.google.com/p/base2/). MooTools originated from [Moo.fx](https://en.wikipedia.org/wiki/Moo.fx), a popular plug-in Proietti produced for Prototype in October 2005, which is still maintained and used.\n\nWhereas Prototype extended—prototyped—many of JavaScript’s native String, Array, and Function objects with additional methods, Proietti desired a framework that (at the time) further extended the native Element object as well to offer greater control of the [DOM](/_glossary/DOM.md).\n\n## Components\n\nMooTools includes a number of components, but not all need to be loaded for each application. Some of the component categories are:\n\n- **Core**: A collection of utility functions that all the other components require.\n- **More**: An official collection of add-ons that extend the Core and provide enhanced functionality.\n- **Class**: The base library for Class object instantiation.\n- **Natives**: A collection of JavaScript Native Object enhancements. The Natives add functionality, compatibility, and new methods that simplify coding.\n- **Element**: Contains a large number of enhancements and compatibility standardization to the HTML Element object.\n- **Fx**: An advanced effects-API to animate page elements.\n- **Request**: Includes [XHR](/_glossary/XHR.md) interface, Cookie, [JSON](/_glossary/JSON.md), and HTML retrieval-specific tools for developers to exploit.\n- **Window**: Provides a cross-browser interface to client-specific information, such as the dimensions of the window.\n\n## Browser compatibility\n\nMooTools is compatible and tested with:\n\n- Safari 3+\n- Internet Explorer 6+\n- Mozilla Firefox 2+\n- Opera 9+\n- Chrome 4+\n\n## Benefits\n\nMooTools provides the user with a number of advantages over native JavaScript. These include:\n\n- An extensible and modular framework allowing developers to choose their own customized combination of components.\n- MooTools follows object-oriented practices and the DRY principle.\n- An advanced effects component, with optimized transitions such as easing equations used by many Flash developers.\n- Enhancements to the DOM, enabling developers to easily add, modify, select, and delete DOM elements. Storing and retrieving information with Element storage is also supported.\n\nThe framework includes built-in functions for manipulation of CSS, DOM elements, native JavaScript objects, Ajax requests, DOM effects, and more. MooTools also provides a detailed, coherent API as well as a custom downloads module allowing developers to download only the modules and dependencies they need for a particular app.\n\n## Emphasis on modularity and reusability\n\nEvery JavaScript framework has its philosophy, and MooTools is interested in taking full advantage of the flexibility and power of JavaScript in a way that emphasizes greater modularity and code reuse. MooTools accomplishes these goals in a way that is intuitive to a developer coming from a class-based inheritance language like Java with the MooTools **Class** object.\n\n**Class** is an object of key/value pairs that can contain either properties or methods (functions). **Class** is effortlessly mixed and extended with other Class instantiations allowing for the greatest focus of MooTools: Code reuse achieved through maximizing the power of JavaScript’s prototypical inheritance, but in a **Class** object syntax more familiar to classical inheritance models.\n\n## Object-oriented programming\n\nMooTools contains a robust Class creation and inheritance system that resembles most classically based Object-oriented programming languages. For example, the following is MooTools’ equivalent of the examples in Wikipedia’s polymorphism page:\n\n```js\nvar Animal = new Class({\n initialize: function(name) {\n this.name = name;\n }\n});\n\nvar Cat = new Class({\n Extends: Animal,\n\n talk: function() {\n return 'Meow!';\n }\n});\n\nvar Dog = new Class({\n Extends: Animal,\n\n talk: function() {\n return 'Arf! Arf';\n }\n});\n\nvar animals = {\n a: new Cat('Missy'),\n b: new Cat('Mr. Bojangles'),\n c: new Dog('Lassie')\n};\n\nObject.each(animals, function(animal) {\n alert(animal.name + ': ' + animal.talk());\n});\n \n// alerts the following:\n//\n// Missy: Meow!\n// Mr. Bojangles: Meow!\n// Lassie: Arf! Arf!\n```\n\n----------\n\n*Source:*\n\n- [MooTools](https://en.wikipedia.org/wiki/MooTools)*. From Wikipedia, the free encyclopedia*\n- [MooTools](http://mootools.net/)*. MooTools official site.*\n", "html": "MooTools (My Object-Oriented Tools) is a lightweight, object-oriented JavaScript framework. It is released under the free, open-source MIT License. It is used on more than 4% of all websites, and is one of the most popular JavaScript libraries.
\n\n\nMooTools is a collection of JavaScript utilities designed for the intermediate to advanced JavaScript developer. It allows you to write powerful and flexible code with its elegant, well documented, and coherent APIs.
\nMooTools code is extensively documented and easy to read, enabling you to extend the functionality to match your requirements.
\n— Official MooTools site.
\n
Valerio Proietti first authored the framework and released it in September 2006 taking as his inspiration Prototype and Dean Edward’s base2. MooTools originated from Moo.fx, a popular plug-in Proietti produced for Prototype in October 2005, which is still maintained and used.
\nWhereas Prototype extended—prototyped—many of JavaScript’s native String, Array, and Function objects with additional methods, Proietti desired a framework that (at the time) further extended the native Element object as well to offer greater control of the DOM.
\nMooTools includes a number of components, but not all need to be loaded for each application. Some of the component categories are:
\nMooTools is compatible and tested with:
\nMooTools provides the user with a number of advantages over native JavaScript. These include:
\nThe framework includes built-in functions for manipulation of CSS, DOM elements, native JavaScript objects, Ajax requests, DOM effects, and more. MooTools also provides a detailed, coherent API as well as a custom downloads module allowing developers to download only the modules and dependencies they need for a particular app.
\nEvery JavaScript framework has its philosophy, and MooTools is interested in taking full advantage of the flexibility and power of JavaScript in a way that emphasizes greater modularity and code reuse. MooTools accomplishes these goals in a way that is intuitive to a developer coming from a class-based inheritance language like Java with the MooTools Class object.
\nClass is an object of key/value pairs that can contain either properties or methods (functions). Class is effortlessly mixed and extended with other Class instantiations allowing for the greatest focus of MooTools: Code reuse achieved through maximizing the power of JavaScript’s prototypical inheritance, but in a Class object syntax more familiar to classical inheritance models.
\nMooTools contains a robust Class creation and inheritance system that resembles most classically based Object-oriented programming languages. For example, the following is MooTools’ equivalent of the examples in Wikipedia’s polymorphism page:
\nvar Animal = new Class({\n initialize: function(name) {\n this.name = name;\n }\n});\n\nvar Cat = new Class({\n Extends: Animal,\n\n talk: function() {\n return 'Meow!';\n }\n});\n\nvar Dog = new Class({\n Extends: Animal,\n\n talk: function() {\n return 'Arf! Arf';\n }\n});\n\nvar animals = {\n a: new Cat('Missy'),\n b: new Cat('Mr. Bojangles'),\n c: new Dog('Lassie')\n};\n\nObject.each(animals, function(animal) {\n alert(animal.name + ': ' + animal.talk());\n});\n\n// alerts the following:\n//\n// Missy: Meow!\n// Mr. Bojangles: Meow!\n// Lassie: Arf! Arf!\nSource:
\n\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/MOOTOOLS.md" }, { "name": "Nightmare", "description": "a high-level browser automation library", "markdown": "\n\n# Nightmare\n\n[Nightmare](http://nightmarejs.org/) is a high-level browser automation library.\n\nThe goal is to expose just a few simple methods, and have an API that feels synchronous for each block of scripting, rather than deeply nested callbacks. It is designed for automating tasks across sites that do not have APIs.\n\nUnder the cover, it uses [Electron](http://electron.atom.io/), which is similar to [PhantomJS](/_glossary/PHANTOMJS.md) but faster and more modern.\n", "html": "Nightmare is a high-level browser automation library.
\nThe goal is to expose just a few simple methods, and have an API that feels synchronous for each block of scripting, rather than deeply nested callbacks. It is designed for automating tasks across sites that do not have APIs.
\nUnder the cover, it uses Electron, which is similar to PhantomJS but faster and more modern.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/NIGHTMARE.md" }, { "name": "NightwatchJS", "description": "a framework for browser automated testing", "markdown": "\n\n# NightwatchJS\n\n[NightwatchJS](http://nightwatchjs.org/) is an extensible, open-source JavaScript testing framework that runs in [Node.js](/_glossary/NODEJS.md). It has clean syntax, a built-in test runner, support for Cloud providers such as SauceLabs or BrowserStack, continuous integration such as Teamcity, Jenkins etc. NightwatchJS also supports CSS and XPath selectors.\n", "html": "NightwatchJS is an extensible, open-source JavaScript testing framework that runs in Node.js. It has clean syntax, a built-in test runner, support for Cloud providers such as SauceLabs or BrowserStack, continuous integration such as Teamcity, Jenkins etc. NightwatchJS also supports CSS and XPath selectors.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/NIGHTWATCHJS.md" }, { "name": "Node.js", "description": "a cross-platform runtime environment for developing server-side applications built on V8 engine", "markdown": "\n\n# Node.js\n\n[Node.js](https://nodejs.org/en/) is an open-source, cross-platform runtime environment for developing server-side web applications built on Chrome’s [V8](/_glossary/V8.md) JavaScript engine. These applications are written in JavaScript and can be run within the Node.js runtime.\n\nNode.js uses an event-driven, non-blocking I/O (input/output) model that makes it lightweight and efficient as well as optimized for real-time web applications’ throughput and scalability.\n\nIts work is hosted and supported by the [Node.js Foundation](https://nodejs.org/en/foundation/), a collaborative project at Linux Foundation.\n", "html": "Node.js is an open-source, cross-platform runtime environment for developing server-side web applications built on Chrome’s V8 JavaScript engine. These applications are written in JavaScript and can be run within the Node.js runtime.
\nNode.js uses an event-driven, non-blocking I/O (input/output) model that makes it lightweight and efficient as well as optimized for real-time web applications’ throughput and scalability.
\nIts work is hosted and supported by the Node.js Foundation, a collaborative project at Linux Foundation.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/NODEJS.md" }, { "name": "npm", "description": "a utility to help publishing packages to, and installing from, an npm repository", "markdown": "\n\n# npm\n\n[npm](https://www.npmjs.com/) is a utility to help publishing packages to, and installing from, an npm repository. The repository npmjs.com is the best known, and contains many useful community written and tested packages.\n", "html": "npm is a utility to help publishing packages to, and installing from, an npm repository. The repository npmjs.com is the best known, and contains many useful community written and tested packages.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/NPM.md" }, { "name": "nvm", "description": "a utility to help run multiple versions of Node.js on the same machine", "markdown": "\n\n# nvm\n\n[nvm](https://github.com/creationix/nvm/blob/master/README.markdown) is a utility to help run multiple versions of [Node.js](/_glossary/NODEJS.md) (and its branches) on the same machine. It can install, list, and choose versions. It is analogous to [RVM](https://rvm.io/) (Ruby Version Manager).\n", "html": "nvm is a utility to help run multiple versions of Node.js (and its branches) on the same machine. It can install, list, and choose versions. It is analogous to RVM (Ruby Version Manager).
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/NVM.md" }, { "name": "Observer Pattern", "description": "a software design pattern in which an object, called the subject, maintains a list of its dependents, called observers, and notifies them automatically of any state changes, usually by calling one of their methods", "markdown": "\n\n# Observer Pattern\n\nThe [observer pattern](https://en.wikipedia.org/wiki/Observer_pattern) is a software design pattern in which an object, called the subject, maintains a list of its dependents, called observers, and notifies them automatically of any state changes, usually by calling one of their methods. It is mainly used to implement distributed event handling systems. The Observer pattern is also a key part in the familiar MVC architectural pattern. The observer pattern is implemented in numerous programming libraries and systems, including almost all GUI toolkits.\n\nThe observer pattern can cause memory leaks, known as the [lapsed listener problem](https://en.wikipedia.org/wiki/Lapsed_listener_problem), because in basic implementation it requires both explicit registration and explicit deregistration, as in the dispose pattern, because the subject holds strong references to the observers, keeping them alive. This can be prevented by the subject holding weak references to the observers.\n\n## Definition\n\nDefine a one-to-many dependency between objects so that when one object changes state, all its dependents are notified and updated automatically.\n\n## Summary\n\nThe Observer pattern offers a subscription model in which objects subscribe to an event and get notified when the event occurs. This pattern is the cornerstone of event driven programming, including JavaScript. The Observer pattern facilitates good object-oriented design and promotes loose coupling.\n\nWhen building web apps you end up writing many event handlers. Event handlers are functions that will be notified when a certain event fires. These notifications optionally receive an event argument with details about the event (for example the x and y position of the mouse at a click event).\n\nThe event and event-handler paradigm in JavaScript is the manifestation of the Observer design pattern. Another name for the Observer pattern is Pub/Sub, short for Publication/Subscription.\n\n## Diagram\n\n\n\nThe objects participating in this pattern are:\n\n- **Subject** - In sample code: `Click`\n - maintains list of observers. Any number of Observer objects may observe a Subject\n - implements an interface that lets observer objects subscribe or unsubscribe\n - sends a notification to its observers when its state changes\n- **Observers** - In sample code: `clickHandler`\n - has a function signature that can be invoked when Subject changes (i.e. event occurs)\n\n## Example\n\nThe `Click` object represents the *Subject*. The `clickHandler` function is the subscribing *Observer*. This handler subscribes, unsubscribes, and then subscribes itself while events are firing. It gets notified only of events #1 and #3.\n\nNotice that the fire method accepts two arguments. The first one has details about the event and the second one is the context, that is, the this value for when the eventhandlers are called. If no context is provided this will be bound to the global object (`window`).\n\nThe `log` function is a helper which collects and displays results.\n\n```js\nclass Click {\n constructor() {\n this.handlers = []; // observers\n }\n\n subscribe(fn) {\n this.handlers.push(fn);\n }\n\n unsubscribe(fn) {\n this.handlers = this.handlers.filter(item => {\n return item !== fn ? item : null;\n });\n }\n\n fire(o, thisObj) {\n let scope = thisObj || window;\n \n this.handlers.forEach(item => { item.call(scope, o) });\n }\n}\n\n// log helper \nlet log = (function() {\n let log = '';\n\n return {\n add: msg => { log += msg + '\\n'; },\n show: () => { alert(log); log = ''; }\n }\n})();\n\nfunction run() {\n var click = new Click(),\n clickHandler = item => { log.add('fired: ' + item); };\n\n click.subscribe(clickHandler);\n click.fire('event #1');\n click.unsubscribe(clickHandler);\n click.fire('event #2');\n click.subscribe(clickHandler);\n click.fire('event #3');\n\n log.show();\n}\n\nrun();\n```\n\n----------\n\n*Source:*\n\n- [Observer pattern](https://en.wikipedia.org/wiki/Observer_pattern)*. From Wikipedia, the free encyclopedia.*\n- [Observer](http://www.dofactory.com/javascript/observer-design-pattern)*. Observer JavaScript Design Pattern with examples.*\n", "html": "The observer pattern is a software design pattern in which an object, called the subject, maintains a list of its dependents, called observers, and notifies them automatically of any state changes, usually by calling one of their methods. It is mainly used to implement distributed event handling systems. The Observer pattern is also a key part in the familiar MVC architectural pattern. The observer pattern is implemented in numerous programming libraries and systems, including almost all GUI toolkits.
\nThe observer pattern can cause memory leaks, known as the lapsed listener problem, because in basic implementation it requires both explicit registration and explicit deregistration, as in the dispose pattern, because the subject holds strong references to the observers, keeping them alive. This can be prevented by the subject holding weak references to the observers.
\nDefine a one-to-many dependency between objects so that when one object changes state, all its dependents are notified and updated automatically.
\nThe Observer pattern offers a subscription model in which objects subscribe to an event and get notified when the event occurs. This pattern is the cornerstone of event driven programming, including JavaScript. The Observer pattern facilitates good object-oriented design and promotes loose coupling.
\nWhen building web apps you end up writing many event handlers. Event handlers are functions that will be notified when a certain event fires. These notifications optionally receive an event argument with details about the event (for example the x and y position of the mouse at a click event).
\nThe event and event-handler paradigm in JavaScript is the manifestation of the Observer design pattern. Another name for the Observer pattern is Pub/Sub, short for Publication/Subscription.
\n
The objects participating in this pattern are:
\nClickclickHandlerThe Click object represents the Subject. The clickHandler function is the subscribing Observer. This handler subscribes, unsubscribes, and then subscribes itself while events are firing. It gets notified only of events #1 and #3.
Notice that the fire method accepts two arguments. The first one has details about the event and the second one is the context, that is, the this value for when the eventhandlers are called. If no context is provided this will be bound to the global object (window).
The log function is a helper which collects and displays results.
class Click {\n constructor() {\n this.handlers = []; // observers\n }\n\n subscribe(fn) {\n this.handlers.push(fn);\n }\n\n unsubscribe(fn) {\n this.handlers = this.handlers.filter(item => {\n return item !== fn ? item : null;\n });\n }\n\n fire(o, thisObj) {\n let scope = thisObj || window;\n\n this.handlers.forEach(item => { item.call(scope, o) });\n }\n}\n\n// log helper \nlet log = (function() {\n let log = '';\n\n return {\n add: msg => { log += msg + '\\n'; },\n show: () => { alert(log); log = ''; }\n }\n})();\n\nfunction run() {\n var click = new Click(),\n clickHandler = item => { log.add('fired: ' + item); };\n\n click.subscribe(clickHandler);\n click.fire('event #1');\n click.unsubscribe(clickHandler);\n click.fire('event #2');\n click.subscribe(clickHandler);\n click.fire('event #3');\n\n log.show();\n}\n\nrun();\nSource:
\nPassport.js is a simple authentication middleware for Node.js that is express compatible.
\nIt focuses primarily on authentication requests through a comprehensive list of strategies including username and password credentials, OAuth (Facebook, Twitter, Google+) and SAML. These strategies are packaged as individual modules to prevent unnecessary dependencies.
\nPassport is also designed to be flexible as it does not mount route and database independent. The API is simple: you provide Passport a request to authenticate, and it provides hooks to control what occurs when authentication succeeds or fails.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/PASSPORTJS.md" }, { "name": "PhantomJS", "description": "a scripted, headless browser used for automating web page interaction", "markdown": "\n\n# PhantomJS\n\n[PhantomJS](http://phantomjs.org/) is a headless WebKit scriptable with a JavaScript API. It has **fast** and **native** support for various web standards: DOM handling, CSS selectors, JSON, Canvas, and SVG.\n\n## Use Cases\n\n- **Headless web testing**. Lightning-fast testing without the browser is now possible! Various [test frameworks](http://phantomjs.org/headless-testing.html) such as [Jasmine](/_glossary/JASMINE.md), Capybara, [QUnit](/_glossary/QUNIT.md), [Mocha](/_glossary/MOCHA.md), WebDriver, YUI Test, BusterJS, FuncUnit, Robot Framework, and many others are supported.\n- **Page automation.** [Access and manipulate](http://phantomjs.org/page-automation.html) web pages with the standard DOM API, or with usual libraries like [jQuery](/_glossary/JQUERY.md).\n- **Screen capture.** Programmatically [capture web contents](http://phantomjs.org/screen-capture.html), including CSS, SVG and Canvas. Build server-side web graphics apps, from a screenshot service to a vector chart rasterizer.\n- **Network monitoring.** Automate performance analysis, track [page loading](http://phantomjs.org/network-monitoring.html) and export as standard HAR format.\n\n## Features\n\n- **Multiplatform**, available on major operating systems: Windows, Mac OS X, Linux, and other Unices.\n- **Fast and native implementation** of web standards: DOM, CSS, JavaScript, Canvas, and SVG. No emulation!\n- **Pure headless (no X11) on Linux**, ideal for continuous integration systems. Also runs on Amazon EC2, Heroku, and Iron.io.\n- **Easy to install**: [Download](http://phantomjs.org/download.html), unpack, and start having fun in just 5 minutes.\n\n## PhantomJS usage\n\nThe PhantomJS JavaScript API can be used to open web pages, take screenshots, execute user actions, and run injected JavaScript in the page context. For example, the following code will open Wikipedia and, upon loading, will save a screenshot to a file and exit.\n\n```js\nconsole.log('Loading a web page');\nvar page = require('webpage').create();\nvar url = 'http://en.wikipedia.org/';\n\npage.open(url, function (status) {\n console.log('Page loaded');\n page.render('wikipedia.org.png');\n phantom.exit();\n});\n```\n\n---\n\n**PhantomJS** is created and maintained by [Ariya Hidayat](http://ariya.ofilabs.com/about) (Twitter: [@ariyahidayat](http://twitter.com/ariyahidayat)), with the help of [many contributors](https://github.com/ariya/phantomjs/contributors). Follow the official Twitter stream [@PhantomJS](http://twitter.com/PhantomJS) to get the frequent development updates.\n", "html": "PhantomJS is a headless WebKit scriptable with a JavaScript API. It has fast and native support for various web standards: DOM handling, CSS selectors, JSON, Canvas, and SVG.
\nThe PhantomJS JavaScript API can be used to open web pages, take screenshots, execute user actions, and run injected JavaScript in the page context. For example, the following code will open Wikipedia and, upon loading, will save a screenshot to a file and exit.
\nconsole.log('Loading a web page');\nvar page = require('webpage').create();\nvar url = 'http://en.wikipedia.org/';\n\npage.open(url, function (status) {\n console.log('Page loaded');\n page.render('wikipedia.org.png');\n phantom.exit();\n});\nPhantomJS is created and maintained by Ariya Hidayat (Twitter: @ariyahidayat), with the help of many contributors. Follow the official Twitter stream @PhantomJS to get the frequent development updates.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/PHANTOMJS.md" }, { "name": "Polymer", "description": "Google’s library for creating Web Components", "markdown": "\n\n# Polymer\n\nWith Google’s [Polymer](https://www.polymer-project.org) library you can extend the vocabulary of HTML with your own custom elements (also known as Web Components) that can carry their own CSS styling and JavaScript code. Once created, these elements can be reused and composed together with other native or custom HTML elements.\n", "html": "With Google’s Polymer library you can extend the vocabulary of HTML with your own custom elements (also known as Web Components) that can carry their own CSS styling and JavaScript code. Once created, these elements can be reused and composed together with other native or custom HTML elements.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/POLYMER.md" }, { "name": "PostCSS", "description": "a tool to transform CSS styles using JavaScript plugins; plugins include autoprefixer, future CSS transpiling, CSS linting and media queries", "markdown": "\n\n# PostCSS\n\n[PostCSS](http://postcss.org/) is a tool to transform CSS styles using JavaScript plugins. Popular plugins include autoprefixer, future CSS transpiling, CSS linting and media queries.\n\n[Autoprefixer](https://github.com/postcss/autoprefixer) helps developer to automatically generate vendor specific prefixes. Take a look at the [interactive demo](http://autoprefixer.github.io/) of Autoprefixer in action\n\n[POSTCSS-cssnext](http://cssnext.io/) is a PostCSS transpiler plugin that transforms new CSS specs into CSS that is more compatible with browsers. This includes CSS nesting, custom selectors and media queries.\n", "html": "PostCSS is a tool to transform CSS styles using JavaScript plugins. Popular plugins include autoprefixer, future CSS transpiling, CSS linting and media queries.
\nAutoprefixer helps developer to automatically generate vendor specific prefixes. Take a look at the interactive demo of Autoprefixer in action
\nPOSTCSS-cssnext is a PostCSS transpiler plugin that transforms new CSS specs into CSS that is more compatible with browsers. This includes CSS nesting, custom selectors and media queries.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/POSTCSS.md" }, { "name": "Promise", "description": "a proxy for a value not necessarily known immediately but that will eventually be resolved", "markdown": "\n\n# Promise\n\nA *Promise* represents a value that may not be available yet but will eventually be resolved at some point in the future. The point is to allow developers to write asynchronous code in a more synchronous fashion, escaping from the popular [callback hell](http://callbackhell.com/).\n\nPromises are not fully supported in all browsers yet (see [support](http://caniuse.com/#feat=promises)), however a lot of libraries mimick their behavior to make them usable right away; [Bluebird](/_glossary/BLUEBIRD.md) is one of them.\n\nFor more information about how promises work and when to use them, there is [complete overview](http://robotlolita.me/2015/11/15/how-do-promises-work.html).\n", "html": "A Promise represents a value that may not be available yet but will eventually be resolved at some point in the future. The point is to allow developers to write asynchronous code in a more synchronous fashion, escaping from the popular callback hell.
\nPromises are not fully supported in all browsers yet (see support), however a lot of libraries mimick their behavior to make them usable right away; Bluebird is one of them.
\nFor more information about how promises work and when to use them, there is complete overview.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/PROMISE.md" }, { "name": "Prototype", "description": "a JavaScript framework that aims to ease development of dynamic web applications. It offers a familiar class-style OO framework, extensive Ajax support, higher-order programming constructs, and easy DOM manipulation", "markdown": "\n\n# Prototype\n\nThe [Prototype](http://prototypejs.org/) JavaScript Framework is a JavaScript framework created by Sam Stephenson in February 2005 as part of the foundation for [AJAX](/_glossary/AJAX.md) support in Ruby on Rails. It is implemented as a single file of JavaScript code, usually named prototype.js. Prototype is distributed standalone, but also as part of larger projects, such as Ruby on Rails, script.aculo.us and Rico.\n\n## Features\n\nPrototype provides various functions for developing JavaScript applications. The features range from programming shortcuts to major functions for dealing with [XHR](/_glossary/XHR.md).\n\nPrototype also provides library functions to support classes and class-based objects, something the JavaScript language lacks. In JavaScript, object creation is prototype-based instead: an object creating function can have a prototype property, and any object assigned to that property will be used as a prototype for the objects created with that function. The Prototype framework is not to be confused with this language feature.\n\n## Sample utility functions\n\n#### The `$()` function\n\nThe **dollar function**, `$()`, can be used as shorthand for the `getElementById` function. To refer to an element in the [DOM](/_glossary/DOM.md) of an HTML page, the usual function identifying an element is:\n\n```js\ndocument.getElementById('id_of_element').style.color = '#ffffff';\n```\n\nThe `$()` function reduces the code to:\n\n```js\n$('id_of_element').setStyle({ color: '#ffffff' });\n```\n\nThe `$()` function can also receive an element as parameter and will return, as in the previous example, a prototype extended object.\n\n```js\nvar domElement = document.getElementById('id_of_element'); // Usual object reference returned\nvar prototypeEnhancedDomElement = $(domElement); // Prototype extended object reference\n```\n\n#### The `$F()` function\n\nBuilding on the `$()` function: the `$F()` function returns the value of the requested form element. For a ‘text’ input, the function will return the data contained in the element. For a ‘select’ input element, the function will return the currently selected value.\n\n```js\n$F('id_of_input_element')\n```\n\n#### The `$$()` function\n\nThe dollar dollar function is Prototype’s *CSS Selector Engine*. It returns all matching elements, following the same rules as a selector in a CSS stylesheet. For example, if you want to get all `` elements with the class “pulsate”, you would use the following:\n\n```js\n$$('a.pulsate')\n```\n\nThis returns a collection of elements. If you are using the script.aculo.us extension of the core Prototype library, you can apply the “pulsate” (blink) effect as follows:\n\n```js\n$$('a.pulsate').each(Effect.Pulsate);\n```\n\n#### The Ajax object\n\nIn an effort to reduce the amount of code needed to run a cross-browser `XMLHttpRequest` function, Prototype provides the `Ajax` object to abstract the different browsers. It has two main methods: `Ajax.Request()` and `Ajax.Updater()`. There are two forms of the `Ajax` object. `Ajax.Request` returns the raw XML output from an AJAX call, while the `Ajax.Updater` will inject the return inside a specified DOM object. The `Ajax.Request` below finds the current values of two HTML form input elements, issues an HTTP POST request to the server with those element name/value pairs, and runs a custom function (called `showResponse` below) when the HTTP response is received from the server:\n\n```js\nnew Ajax.Request('http://localhost/server_script', {\n parameters: {\n value1: $F('form_element_id_1'),\n value2: $F('form_element_id_2')\n },\n onSuccess: showResponse,\n onFailure: showError\n});\n```\n\n## Object-oriented programming\n\nPrototype also adds support for more traditional object-oriented programming. The `Class.create()` method is used to create a new class. A class is then assigned a `prototype` which acts as a blueprint for instances of the class.\n\n```js\nvar FirstClass = Class.create( {\n // The initialize method serves as a constructor\n initialize: function () {\n this.data = 'Hello World';\n }\n});\n```\n\nExtending another class:\n\n```js\nAjax.Request = Class.create( Ajax.Base, { \n // Override the initialize method\n initialize: function(url, options) { \n this.transport = Ajax.getTransport(); \n this.setOptions(options); \n this.request(url); \n }, \n // ...more methods add ... \n});\n```\n\nThe framework function `Object.extend(dest, src)` takes two objects as parameters and copies the properties of the second object to the first one simulating inheritance. The combined object is also returned as a result from the function. As in the example above, the first parameter usually creates the base object, while the second is an anonymous object used solely for defining additional properties. The entire sub-class declaration happens within the parentheses of the function call.\n\n----------\n\n*Source:*\n\n- [Prototype JavaScript Framework](https://en.wikipedia.org/wiki/Prototype_JavaScript_Framework)*. From Wikipedia, the free encyclopedia.*\n- [Prototype JavaScript framework: a foundation for ambitious web applications](http://prototypejs.org/)*. Official site.*\n- [Prototype JavaScript framework](https://github.com/sstephenson/prototype)*. Github.*\n", "html": "The Prototype JavaScript Framework is a JavaScript framework created by Sam Stephenson in February 2005 as part of the foundation for AJAX support in Ruby on Rails. It is implemented as a single file of JavaScript code, usually named prototype.js. Prototype is distributed standalone, but also as part of larger projects, such as Ruby on Rails, script.aculo.us and Rico.
\nPrototype provides various functions for developing JavaScript applications. The features range from programming shortcuts to major functions for dealing with XHR.
\nPrototype also provides library functions to support classes and class-based objects, something the JavaScript language lacks. In JavaScript, object creation is prototype-based instead: an object creating function can have a prototype property, and any object assigned to that property will be used as a prototype for the objects created with that function. The Prototype framework is not to be confused with this language feature.
\n$() functionThe dollar function, $(), can be used as shorthand for the getElementById function. To refer to an element in the DOM of an HTML page, the usual function identifying an element is:
document.getElementById('id_of_element').style.color = '#ffffff';\nThe $() function reduces the code to:
$('id_of_element').setStyle({ color: '#ffffff' });\nThe $() function can also receive an element as parameter and will return, as in the previous example, a prototype extended object.
var domElement = document.getElementById('id_of_element'); // Usual object reference returned\nvar prototypeEnhancedDomElement = $(domElement); // Prototype extended object reference\n$F() functionBuilding on the $() function: the $F() function returns the value of the requested form element. For a ‘text’ input, the function will return the data contained in the element. For a ‘select’ input element, the function will return the currently selected value.
$F('id_of_input_element')\n$$() functionThe dollar dollar function is Prototype’s CSS Selector Engine. It returns all matching elements, following the same rules as a selector in a CSS stylesheet. For example, if you want to get all <a> elements with the class “pulsate”, you would use the following:
$$('a.pulsate')\nThis returns a collection of elements. If you are using the script.aculo.us extension of the core Prototype library, you can apply the “pulsate” (blink) effect as follows:
\n$$('a.pulsate').each(Effect.Pulsate);\nIn an effort to reduce the amount of code needed to run a cross-browser XMLHttpRequest function, Prototype provides the Ajax object to abstract the different browsers. It has two main methods: Ajax.Request() and Ajax.Updater(). There are two forms of the Ajax object. Ajax.Request returns the raw XML output from an AJAX call, while the Ajax.Updater will inject the return inside a specified DOM object. The Ajax.Request below finds the current values of two HTML form input elements, issues an HTTP POST request to the server with those element name/value pairs, and runs a custom function (called showResponse below) when the HTTP response is received from the server:
new Ajax.Request('http://localhost/server_script', {\n parameters: {\n value1: $F('form_element_id_1'),\n value2: $F('form_element_id_2')\n },\n onSuccess: showResponse,\n onFailure: showError\n});\nPrototype also adds support for more traditional object-oriented programming. The Class.create() method is used to create a new class. A class is then assigned a prototype which acts as a blueprint for instances of the class.
var FirstClass = Class.create( {\n // The initialize method serves as a constructor\n initialize: function () {\n this.data = 'Hello World';\n }\n});\nExtending another class:
\nAjax.Request = Class.create( Ajax.Base, { \n // Override the initialize method\n initialize: function(url, options) { \n this.transport = Ajax.getTransport(); \n this.setOptions(options); \n this.request(url); \n }, \n // ...more methods add ... \n});\nThe framework function Object.extend(dest, src) takes two objects as parameters and copies the properties of the second object to the first one simulating inheritance. The combined object is also returned as a result from the function. As in the example above, the first parameter usually creates the base object, while the second is an anonymous object used solely for defining additional properties. The entire sub-class declaration happens within the parentheses of the function call.
Source:
\nThe prototype pattern is a creational design pattern in software development. It is used when the type of objects to create is determined by a prototypical instance, which is cloned to produce new objects. This pattern is used to:
\nnew keyword) when it is prohibitively expensive for a given application.To implement the pattern, declare an abstract base class that specifies a pure virtual clone() method. Any class that needs a “polymorphic constructor” capability derives itself from the abstract base class, and implements the clone() operation.
The client, instead of writing code that invokes the new operator on a hard-coded class name, calls the clone() method on the prototype, calls a factory method with a parameter designating the particular concrete derived class desired, or invokes the clone() method through some mechanism provided by another design pattern.

The objects participating in this pattern are:
\nrun() function.CustomerPrototypeCustomerIn the sample code we have a CustomerPrototype object that clones objects given a prototype object. Its constructor function accepts a prototype of type Customer. Calling the clone method will generate a new Customer object with its property values initialized with the prototype values.
This is the classical implementation of the Prototype pattern, but JavaScript can do this far more effectively using its built-in prototype facility.
\nfunction CustomerPrototype(proto) {\n this.proto = proto;\n\n this.clone = function () {\n var customer = new Customer();\n\n customer.first = proto.first;\n customer.last = proto.last;\n customer.status = proto.status;\n\n return customer;\n };\n}\n\nfunction Customer(first, last, status) {\n this.first = first;\n this.last = last;\n this.status = status;\n\n this.say = function () {\n alert('name: '\n + this.first\n + ' '\n + this.last\n + ', status: '\n + this.status\n );\n };\n}\n\nfunction run() {\n var proto = new Customer('n/a', 'n/a', 'pending');\n var prototype = new CustomerPrototype(proto);\n var customer = prototype.clone();\n customer.say();\n}\n\nrun();\nSource:
\nPuppeteer is a Node library which provides a high-level API to control headless Chrome or Chromium over the DevTools Protocol. It can also be configured to use full (non-headless) Chrome or Chromium.
\nCaution: Puppeteer requires at least Node v6.4.0, but the examples below use async/await which is only supported in Node v7.6.0 or greater.
\nPuppeteer will be familiar to people using other browser testing frameworks. You create an instance\nof Browser, open pages, and then manipulate them with Puppeteer's API.
Example - navigating to https://example.com and saving a screenshot as example.png:
\nSave file as example.js
\nconst puppeteer = require('puppeteer');\n\n(async () => {\n const browser = await puppeteer.launch();\n const page = await browser.newPage();\n await page.goto('https://example.com');\n await page.screenshot({path: 'example.png'});\n\n await browser.close();\n})();\nA pure function is a paradigm from the Functional Programming world.
\nThe main idea is that a pure function respects the following properties:
\n// The following function is not Pure because different calls with same argument will not produce the same output :\nfunction impureAdd (input) {\n return input + Math.Random();\n}\n\n// A way to make a pure function of it is to extract the impredictable part and give this responsibility to the caller :\nfunction pureAdd (input, randomValue) {\n return input + randomValue;\n}\n\nvar randomAdd = pureAdd(5, Math.Random());\n// The following function is not Pure because it has a side effect : it writes in the environnement’s console\nfunction impureFunction (input) {\n var output = computeHashValue(input);\n console.log('computed output:', output);\n return output;\n}\n\n// To make it pure, again, the caller has the responsibility to pass the desired side effects.\nfunction pureFunction (input, traceCallback) {\n var output = computeHashValue(input);\n\n if (traceCallback) {\n traceCallback('computed output:', output);\n }\n\n return output;\n}\n\nvar output = pureFunction('some input', (s) => console.log(s));\nvar applicationState = {\n businessTreshold = 92;\n}\n\n// The following function is not Pure because it relies on a global variable, an external state from the point of view of the function\nfunction impureValidation (inputScore) {\n return input < applicationState.businessTreshold;\n}\n\n// To make it pure, again, the caller has the responsibility to pass the needed state for the function to run\nfunction pureValidation (inputScore, threshold) {\n return input < threshold;\n}\n\nvar output = pureFunction(70, applicationState.businessTreshold);\nSources:
\n\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/PURE_FUNCTION.md" }, { "name": "Q", "description": "a library to create and manage promises", "markdown": "\n\n# Q\n\n[Q](http://documentup.com/kriskowal/q/) is a [promise](/_glossary/PROMISE.md) library providing many more utilities than the native Promise implementation.\n\nList of features:\n\n- Deferred values (old school): `Q.defer`\n- Multiple promises handling: `Q.all, Q.any, Q.spread`\n- Promise creation, resolve and reject: `Q(value), Q.when(value), Q.reject(value)`\n- Convert properties to promises: `Q.get, Q.set`\n- Convert functions to promises: `Q.fcall, Q.invoke`\n- Convert node-based callbacks to promises: `Q.nfcall, Q.ninvoke`\n- Convert timeout functions: `Q.timeout`\n- Support notify functions\n- Support chaining and tapping\n\nReal world example from a [Node.js](/_glossary/NODEJS.md) application:\n\n```js\n// Traditional implementation\nfunction authenticate (req, res, next) {\n User.findOne({ id: req.id }, function (err, user) {\n if (err) {\n return next('not found');\n }\n\n user.save(function (err, response) {\n // ...\n });\n });\n}\n\n// Q Based\nfunction authenticate(req, res, next) {\n return Q(req.id)\n .then(function (id) {\n return Q.nfcall(User, 'findOne', id);\n })\n .then(function (user) {\n return Q.ninvoke(user, 'save');\n })\n .then(function (saved) {\n return res.send(201);\n })\n .catch(function (err) {\n return next(err);\n });\n}\n```\n", "html": "Q is a promise library providing many more utilities than the native Promise implementation.
\nList of features:
\nQ.deferQ.all, Q.any, Q.spreadQ(value), Q.when(value), Q.reject(value)Q.get, Q.setQ.fcall, Q.invokeQ.nfcall, Q.ninvokeQ.timeoutReal world example from a Node.js application:
\n// Traditional implementation\nfunction authenticate (req, res, next) {\n User.findOne({ id: req.id }, function (err, user) {\n if (err) {\n return next('not found');\n }\n\n user.save(function (err, response) {\n // ...\n });\n });\n}\n\n// Q Based\nfunction authenticate(req, res, next) {\n return Q(req.id)\n .then(function (id) {\n return Q.nfcall(User, 'findOne', id);\n })\n .then(function (user) {\n return Q.ninvoke(user, 'save');\n })\n .then(function (saved) {\n return res.send(201);\n })\n .catch(function (err) {\n return next(err);\n });\n}\nQUnit is a JavaScript unit testing framework. While heavily used by the jQuery Project for testing jQuery, jQuery UI and jQuery Mobile, it is a generic framework to test any JavaScript code. It supports server-side (e.g. node.js) and client-side environments.
\nQUnit’s assertion methods follow the CommonJS unit testing specification, which itself was influenced to some degree by QUnit.
\nQUnit was originally developed by John Resig as part of jQuery. In 2008 it was extracted from the jQuery unit test source code to form its own project and became known as “QUnit”. This allowed others to start using it for writing their unit tests. While the initial version of QUnit used jQuery for interaction with the DOM, a rewrite in 2009 made QUnit completely standalone.
\nQUnit.module(string) - Defines a module, a grouping of one or more tests.QUnit.test(string, function) - Defines a test.QUnit uses a set of assertion method to provide semantic meaning in unit tests:
\nassert.ok(boolean, string) - Asserts that the provided value casts to boolean true.assert.equal(value1, value2, message) - Compares two values, using the double-equal operator.assert.deepEqual(value1, value2, message) - Compares two values based on their content, not just their identity.assert.strictEqual(value1, value2, message) - Strictly compares two values, using the triple-equal operator.A basic example would be as follows:
\nQUnit.test('a basic test example', function (assert) {\n var obj = {};\n\n assert.ok(true, 'Boolean true'); // passes\n assert.ok(1, 'Number one'); // passes\n assert.ok(false, 'Boolean false'); // fails\n\n obj.start = 'Hello';\n obj.end = 'Ciao';\n assert.equal(obj.start, 'Hello', 'Opening greet'); // passes\n assert.equal(obj.end, 'Goodbye', 'Closing greet'); // fails\n});\nSource:
\nRamda is a library designed specifically for a functional programming style, one that makes it easy to create functional pipelines, one that never mutates user data.
\nRamda makes it very easy to build functions as sequences of simpler functions, each of which transforms the data and passes it along to the next.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/RAMDA.md" }, { "name": "React", "description": "a library developed and used at Facebook for building user interfaces", "markdown": "\n\n# React\n\n[React](https://facebook.github.io/react/) is a library developed and used at Facebook for building user interfaces. It can be seen as the V in MVC as it makes no assumptions about the rest of the technology stack. Using [React Native](#react-native) it can even be used to power native apps.\n\nIn React you can write HTML directly in JS using an XML-like syntax called [JSX](/_glossary/JSX.md). JSX compiles to JS and is optional, but does make the code more expressive.\n\nData flow in React is one-way which makes it easier to reason about and avoid mistakes. This quality can be enhanced using [Flux](/_glossary/FLUX.md), Facebook’s complementary application architecture, or [Redux](/_glossary/REDUX.md) which many people see as a “better Flux”.\n\n# React Native\n\n[React Native](https://facebook.github.io/react-native/) section to be completed.\n", "html": "React is a library developed and used at Facebook for building user interfaces. It can be seen as the V in MVC as it makes no assumptions about the rest of the technology stack. Using React Native it can even be used to power native apps.
\nIn React you can write HTML directly in JS using an XML-like syntax called JSX. JSX compiles to JS and is optional, but does make the code more expressive.
\nData flow in React is one-way which makes it easier to reason about and avoid mistakes. This quality can be enhanced using Flux, Facebook’s complementary application architecture, or Redux which many people see as a “better Flux”.
\nReact Native section to be completed.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/REACT.md" }, { "name": "Redux", "description": "a predictable state container for apps", "markdown": "\n\n# Redux\n\n[Redux](http://redux.js.org/) is a predictable state container for JavaScript apps, which is a fancy way of saying it controls application state and state mutations. It does so by keeping state in a store, which is the single source of truth.\n\nRedux is an alternative to [Flux](/_glossary/FLUX.md) and used a lot together with [React](/_glossary/REACT.md), but you can use it with any other view library.\n", "html": "Redux is a predictable state container for JavaScript apps, which is a fancy way of saying it controls application state and state mutations. It does so by keeping state in a store, which is the single source of truth.
\nRedux is an alternative to Flux and used a lot together with React, but you can use it with any other view library.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/REDUX.md" }, { "name": "RequireJS", "description": "a browser based module loader using AMD", "markdown": "\n\n# RequireJS\n\n[RequireJS](http://requirejs.org/) section to be completed.\n", "html": "RequireJS section to be completed.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/REQUIREJS.md" }, { "name": "Revealing Module Pattern", "description": "a design pattern conceptually based on the Module Pattern. The only difference is that the *revealing module pattern* was engineered as a way to ensure that all methods and variables are kept private until they are explicitly exposed", "markdown": "\n\n# Revealing Module Pattern\n\nThis pattern is the same concept as the [module pattern](/_glossary/MODULE_PATTERN.md) in that it focuses on public & private methods. The only difference is that the revealing module pattern was engineered as a way to ensure that all methods and variables are kept private until they are explicitly exposed; usually through an object literal returned by the closure from which it’s defined. Personally, I like this approach for vanilla JavaScript as it puts a clear emphasis on both the intent of the developer and the module itself.\n\n## Advantages\n\n- Cleaner approach for developers\n- Supports private data\n- Less clutter in the global namespace\n- Localization of functions and variables through closures\n- The syntax of our scripts are even more consistent\n- Explicitly defined public methods and variables which lead to increased readability\n\n## Disadvantages\n\n- Private methods are unaccessible.\n- Private methods and functions lose extendability since they are unaccessible (see my comment in the previous bullet point).\n- It’s harder to patch public methods and variables that are referred to by something private.\n\n## Example\n\n```js\nvar MyModule = (function(window, undefined) {\n function myMethod() {\n console.log('my method');\n }\n\n function myOtherMethod() {\n console.log('my other method');\n }\n\n // explicitly return public methods when this object is instantiated\n return {\n someMethod: myMethod,\n someOtherMethod: myOtherMethod\n };\n})(window);\n\n// example usage\nMyModule.myMethod(); // undefined\nMyModule.myOtherMethod(); // undefined\nMyModule.someMethod(); // prints 'my method'\nMyModule.someOtherMethod(); // prints 'my other method'\n```\n\nThis pattern can also be implemented using a privately shared cache:\n\n```js\nvar MyModule = (function(window,undefined) {\n // this object is used to store private variables and methods across multiple instantiations\n var privates = {};\n\n function MyModule() {\n this.myMethod = function myMethod() {\n console.log('my method');\n };\n\n this.myOtherMethod = function myOtherMethod() {\n console.log('my other method');\n };\n }\n\n return MyModule;\n})(window);\n\n// example usage\nvar myMod = new MyModule();\nmyMod.myMethod(); // prints 'my method'\nmyMod.myOtherMethod(); // prints 'my other method'\n```\n\n----------\n\n*Source:*\n\n- [The Revealing Module Pattern](https://carldanley.com/js-revealing-module-pattern/)\n- [The Module Pattern](https://carldanley.com/js-module-pattern/#file-module-pattern-example-2-js-L1)\n", "html": "This pattern is the same concept as the module pattern in that it focuses on public & private methods. The only difference is that the revealing module pattern was engineered as a way to ensure that all methods and variables are kept private until they are explicitly exposed; usually through an object literal returned by the closure from which it’s defined. Personally, I like this approach for vanilla JavaScript as it puts a clear emphasis on both the intent of the developer and the module itself.
\nvar MyModule = (function(window, undefined) {\n function myMethod() {\n console.log('my method');\n }\n\n function myOtherMethod() {\n console.log('my other method');\n }\n\n // explicitly return public methods when this object is instantiated\n return {\n someMethod: myMethod,\n someOtherMethod: myOtherMethod\n };\n})(window);\n\n// example usage\nMyModule.myMethod(); // undefined\nMyModule.myOtherMethod(); // undefined\nMyModule.someMethod(); // prints 'my method'\nMyModule.someOtherMethod(); // prints 'my other method'\nThis pattern can also be implemented using a privately shared cache:
\nvar MyModule = (function(window,undefined) {\n // this object is used to store private variables and methods across multiple instantiations\n var privates = {};\n\n function MyModule() {\n this.myMethod = function myMethod() {\n console.log('my method');\n };\n\n this.myOtherMethod = function myOtherMethod() {\n console.log('my other method');\n };\n }\n\n return MyModule;\n})(window);\n\n// example usage\nvar myMod = new MyModule();\nmyMod.myMethod(); // prints 'my method'\nmyMod.myOtherMethod(); // prints 'my other method'\nSource:
\n\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/REVEALING_MODULE_PATTERN.md" }, { "name": "rnpm", "description": "a package manager to ease React Native development", "markdown": "\n\n# rnpm\n\n[rnpm](https://github.com/rnpm/rnpm) is built to ease [React Native](/_glossary/REACT.md#react-native) development by automatically linking native dependencies to your iOS/Android project.", "html": "rnpm is built to ease React Native development by automatically linking native dependencies to your iOS/Android project.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/RNPM.md" }, { "name": "RxJS", "description": "a library for asynchronous programming using observable streams", "markdown": "\n\n# RxJS\n\n[RxJS](https://github.com/Reactive-Extensions/RxJS) is a library in the [ReactiveX](http://reactivex.io/) family of functional reactive programming libraries. It allows you to develop programs that respond to asynchronous events by composing sequences of observable streams.\n\nObservable streams can send zero or more “data” notifications and terminate with either an “completed” or an “error” notification. Subsequent streams can combine and remix these notifications into new observable patterns, making it possible to compose rich sequences of asynchronous events that clean up resources appropriately when done.\n\nRxJS is available under an Apache license. It is developed by Microsoft Open Source and numerous third-party contributors.\n", "html": "RxJS is a library in the ReactiveX family of functional reactive programming libraries. It allows you to develop programs that respond to asynchronous events by composing sequences of observable streams.
\nObservable streams can send zero or more “data” notifications and terminate with either an “completed” or an “error” notification. Subsequent streams can combine and remix these notifications into new observable patterns, making it possible to compose rich sequences of asynchronous events that clean up resources appropriately when done.
\nRxJS is available under an Apache license. It is developed by Microsoft Open Source and numerous third-party contributors.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/RXJS.md" }, { "name": "Sails", "description": "a realtime MVC Framework for Node.js", "markdown": "\n\n# Sails\n\n[Sails](http://sailsjs.org/) is a web framework that makes it easy to build custom, enterprise-grade [Node.js](/_glossary/NODEJS.md) apps. It is designed to resemble the MVC architecture from frameworks like Ruby on Rails, but with support for the more modern, data-oriented style of web app development. It’s especially good for building realtime features like chat.\n", "html": "Sails is a web framework that makes it easy to build custom, enterprise-grade Node.js apps. It is designed to resemble the MVC architecture from frameworks like Ruby on Rails, but with support for the more modern, data-oriented style of web app development. It’s especially good for building realtime features like chat.
\n", "url": "https://github.com/HugoGiraudel/SJSJ/blob/master/_glossary/SAILS.md" }, { "name": "Singleton Pattern", "description": "a design pattern that restricts the instantiation of a class to one object", "markdown": "\n\n# Singleton Pattern\n\nIn software engineering, the [singleton pattern](https://en.wikipedia.org/wiki/Singleton_pattern) is a design pattern that restricts the instantiation of a class to one object. This is useful when exactly one object is needed to coordinate actions across the system. The concept is sometimes generalized to systems that operate more efficiently when only one object exists, or that restrict the instantiation to a certain number of objects. The term comes from the [mathematical concept of a singleton](https://en.wikipedia.org/wiki/Singleton_(mathematics)).\n\nThe Singleton Pattern limits the number of instances of a particular object to just one. This single instance is called the singleton.\n\nSingletons are useful in situations where system-wide actions need to be coordinated from a single central place. An example is a database connection pool. The pool manages the creation, destruction, and lifetime of all database connections for the entire application ensuring that no connections are ‘lost’.\n\nSingletons reduce the need for global variables which is particularly important in JavaScript because it limits namespace pollution and associated risk of name collisions. The [Module pattern](MODULE_PATTERN.md) is JavaScript’s manifestation of the Singleton pattern.\n\n## Common uses\n\n- The [Abstract Factory](https://en.wikipedia.org/wiki/Abstract_factory_pattern), [Builder](https://en.wikipedia.org/wiki/Builder_pattern), and [Prototype](/_glossary/PROTOTYPE_PATTERN.md) patterns can use Singletons in their implementation.\n- [Facade](/_glossary/FACADE_PATTERN.md) objects are often singletons because only one Facade object is required.\n- [State](https://en.wikipedia.org/wiki/State_pattern) objects are often singletons.\nSingletons are often preferred to global variables because:\n - They do not pollute the global namespace (or, in languages with namespaces, their containing namespace) with unnecessary variables.\n - They permit lazy allocation and initialization, whereas global variables in many languages will always consume resources.\n\n## Structure\n\n\n\nThe objects participating in this pattern are:\n\n- `Singleton` - In sample code: `Singleton`\n - defines `getInstance()` which returns the unique instance.\n - responsible for creating and managing the instance object.\n\n## Example\n\nThe Singleton object is implemented as an [IIFE](/_glossary/IIFE.md). The function executes immediately by wrapping it in brackets followed by two additional brackets. It is called anonymous because it doesn’t have a name.\n\n#### Example 1\n\n```js\nvar Singleton = (function() {\n var instance;\n\n // Private methods and fields\n // ... \n\n // Constructor\n function Singleton() {\n if (!instance) {\n instance = this;\n }\n\n return instance;\n\n // Public fields\n }\n\n // Public methods\n Singleton.prototype.test = function() {};\n\n return Singleton;\n})();\n\nfunction run() {\n var instance1 = new Singleton()\n var instance2 = new Singleton()\n \n console.assert(instance1 === instance2);\n}\n\nrun();\n```\n\n#### Example 2\n\nThe `getInstance` method is Singleton’s gatekeeper. It returns the one and only instance of the object while maintaining a private reference to it which is not accessible to the outside world.\n\nThe `getInstance` method demonstates another design pattern called **Lazy Load**. **Lazy Load** checks if an instance has already been created; if not, it creates one and stores it for future reference. All subsequent calls will receive the stored instance. Lazy loading is a CPU and memory saving technique by creating objects only when absolutely necessary.\n\n```js\nvar Singleton = (function () {\n var instance;\n \n function createInstance() {\n var object = new Object('I am the instance');\n return object;\n }\n \n return {\n getInstance: function () {\n if (!instance) {\n instance = createInstance();\n }\n\n return instance;\n }\n };\n})();\n \nfunction run() {\n var instance1 = Singleton.getInstance();\n var instance2 = Singleton.getInstance();\n \n console.assert(instance1 === instance2);\n}\n\nrun();\n```\n\n----------\n\n*Source:*\n- [Singleton pattern](https://en.wikipedia.org/wiki/Singleton_pattern)*. From Wikipedia, the free encyclopedia.*\n- [Singleton](http://www.dofactory.com/javascript/singleton-design-pattern)*. Singleton JavaScript Design Pattern with examples.*\n", "html": "In software engineering, the singleton pattern is a design pattern that restricts the instantiation of a class to one object. This is useful when exactly one object is needed to coordinate actions across the system. The concept is sometimes generalized to systems that operate more efficiently when only one object exists, or that restrict the instantiation to a certain number of objects. The term comes from the mathematical concept of a singleton).
\nThe Singleton Pattern limits the number of instances of a particular object to just one. This single instance is called the singleton.
\nSingletons are useful in situations where system-wide actions need to be coordinated from a single central place. An example is a database connection pool. The pool manages the creation, destruction, and lifetime of all database connections for the entire application ensuring that no connections are ‘lost’.
\nSingletons reduce the need for global variables which is particularly important in JavaScript because it limits namespace pollution and associated risk of name collisions. The Module pattern is JavaScript’s manifestation of the Singleton pattern.
\n
The objects participating in this pattern are:
\nSingleton - In sample code: SingletongetInstance() which returns the unique instance.The Singleton object is implemented as an IIFE. The function executes immediately by wrapping it in brackets followed by two additional brackets. It is called anonymous because it doesn’t have a name.
\nvar Singleton = (function() {\n var instance;\n\n // Private methods and fields\n // ... \n\n // Constructor\n function Singleton() {\n if (!instance) {\n instance = this;\n }\n\n return instance;\n\n // Public fields\n }\n\n // Public methods\n Singleton.prototype.test = function() {};\n\n return Singleton;\n})();\n\nfunction run() {\n var instance1 = new Singleton()\n var instance2 = new Singleton()\n\n console.assert(instance1 === instance2);\n}\n\nrun();\nThe getInstance method is Singleton’s gatekeeper. It returns the one and only instance of the object while maintaining a private reference to it which is not accessible to the outside world.
The getInstance method demonstates another design pattern called Lazy Load. Lazy Load checks if an instance has already been created; if not, it creates one and stores it for future reference. All subsequent calls will receive the stored instance. Lazy loading is a CPU and memory saving technique by creating objects only when absolutely necessary.
var Singleton = (function () {\n var instance;\n\n function createInstance() {\n var object = new Object('I am the instance');\n return object;\n }\n\n return {\n getInstance: function () {\n if (!instance) {\n instance = createInstance();\n }\n\n return instance;\n }\n };\n})();\n\nfunction run() {\n var instance1 = Singleton.getInstance();\n var instance2 = Singleton.getInstance();\n\n console.assert(instance1 === instance2);\n}\n\nrun();\nSource:
\n